
Python:PyTorch 初识 (七十五)
我们将以下所有概念关联到一起:Python、Numpy/Pandas/Matplotlib、线性代数和神经网络,并学习 PyTorch。 PyTorch 是一个 Python 开源库,可以用于轻松地训练神经网络。
PyTorch 简介
在这节课,我们将学习如何使用 PyTorch 构建深度学习模型。PyTorch 于 2017 年初推出,对深度学习领域带来了深远的影响。它是由 Facebook 的 AI 团队开发的,已经被各行各业和各个学术领域采用。根据我个人的经验,它是开发和训练神经网络的最佳框架。学完这节课后,你将训练一个能够轻松地对猫狗图像进行分类的深度学习模型。
首先,我将简单介绍 PyTorch,在此部分,我们将介绍张量,即 PyTorch 的主要数据结构。我将演示如何创建张量、如何简化运算,以及张量如何与 Numpy 交互。
然后,你将学习模块 Autograd,PyTorch 使用该模块计算训练神经网络的梯度。我认为 Autograd 非常强大。它会为你完成整个反向传播工作:计算网络中每次运算的梯度,然后使用这些梯度更新网络权重。
接着,你将使用 PyTorch 构建网络并在其中向前运行数据。然后,你将定义损失和优化方法,并用手写数字数据集训练神经网络。你还将学习如何验证你的神经网络是否可以通过验证进行泛化。
但是,你将发现你的网络在更复杂的图像上的效果不太好。你将学习如何使用预训练的神经网络改善分类器的性能,这种方法也被称作迁移学习。
张量(tensors)
张量是向量和矩阵的泛华,例如向量是一维张量,有一行值,矩阵是二维张量,是一个长方形,有行和列,这些数字排列在二维空间中。张量是你将在 PyTorch 中使用的主要数据结构,当你使用张量时,如果能够在脑中想象出他们的结构,对理解很有帮助,在下边你讲学习如何操作。
通过 PyTorch 进行深度学习的简介
在此 notebook 中,你将了解 PyTorch,一款用于构建和训练神经网络的框架。PyTorch 在很多方面的行为都和你喜欢的 Numpy 数组很像。这些 Numpy 数组毕竟只是张量。PyTorch 采用这些张量并使我们能够轻松地将张量移到 GPU 中,以便在训练神经网络时加快处理速度。它还提供了一个自动计算梯度(用于反向传播!)的模块,以及另一个专门用于构建神经网络的模块。总之,与 TensorFlow 和其他框架相比,PyTorch 与 Python 和 Numpy/Scipy 堆栈更协调。
神经网络
深度学习以人工神经网络为基础,而后者从上世纪 50 年代末就出现了。神经网络由像神经元一样的单个部分组成,这些部分通常称为单元或直接叫做“神经元”。每个单元都具有一定数量的加权输入。我们对这些加权输入求和(线性组合),然后将结果传递给激活函数,以获得单元的输出 。
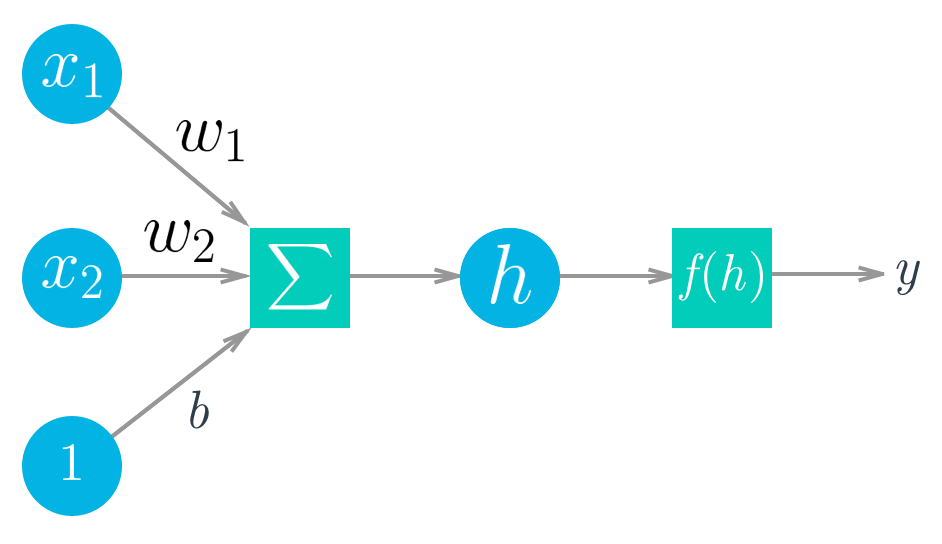
数学公式如下所示:
$$
\begin{align}
y &= f(w_1 x_1 + w_2 x_2 + b) \
y &= f\left(\sum_i w_i x_i \right)
\end{align}
$$
对于向量来说,为两个向量的点积/内积:
$$
h = \begin{bmatrix}
x_1 \, x_2 \cdots x_n
\end{bmatrix}
\cdot
\begin{bmatrix}
w_1 \
w_2 \
\vdots \
w_n
\end{bmatrix}
$$
堆叠起来!
我们可以将这些单元神经元组合为层和堆栈,形成神经元网络。一个神经元层的输出变成另一层的输入。对于多个输入单元和输出单元,我们现在需要将权重表示为矩阵。
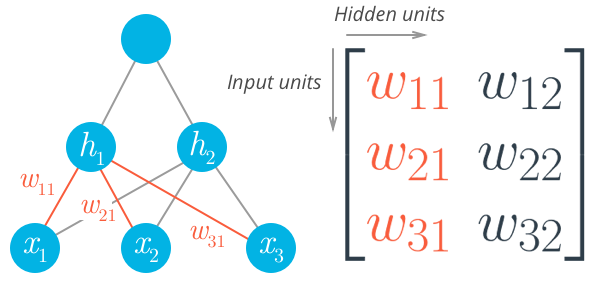
我们再次能够用矩阵以数学方式表示这些数据,并使用矩阵乘法获得一次运算中每个单元的线性组合。例如,隐藏层(此以下公式中为 $h_1$ 和 $h_2$)可以计算为
$$
\vec{h} = [h_1 \, h_2] =
\begin{bmatrix}
x_1 \, x_2 \cdots \, xn
\end{bmatrix}
\cdot
\begin{bmatrix}
w{11} & w{12} \
w{21} &w{22} \
\vdots &\vdots \
w{n1} &w_{n2}
\end{bmatrix}
$$
我们通过将隐藏层当做输出单元的输入,可以算出这个小型网络的输出。网络输出简单地表示为
$$
y = f_2 ! \left(\, f_1 ! \left(\vec{x} \, \mathbf{W_1}\right) \mathbf{W_2} \right)
$$
张量
实际上神经网络计算只是对张量进行一系列线性代数运算,矩阵是张量的一种形式。向量是一维张量,矩阵是二维张量,包含 3 个索引的数组是三维张量(例如 RGB 颜色图像)。神经网络的基本数据结构是张量,PyTorch(以及几乎所有其他深度学习框架)都是以张量为基础。

介绍了基本知识后,现在该了解如何使用 PyTorch 构建简单的神经网络了。
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import numpy as np
import torch
import helper首先,我们来看看如何处理 PyTorch 张量。这些结构是神经网络和 PyTorch 的基本数据结构,因此请务必理解这些运算的原理。
x = torch.rand(3, 2)
xtensor([[ 0.2219, 0.6481],
[ 0.9546, 0.5206],
[ 0.2628, 0.6034]])y = torch.ones(x.size())
ytensor([[ 1., 1.],
[ 1., 1.],
[ 1., 1.]])z = x + y
ztensor([[ 1.2219, 1.6481],
[ 1.9546, 1.5206],
[ 1.2628, 1.6034]])一般而言,PyTorch 张量的行为和 Numpy 数组相似。它们的索引都以 0 开始,并且支持切片。
z[0]tensor([ 1.2219, 1.6481])z[:, 1:]tensor([[ 1.6481],
[ 1.5206],
[ 1.6034]])张量通常有两种类型的方法,一种方法返回另一个张量,另一种方法原地执行运算。即该张量在内存中的值发生了改变,没有创建新的张量。原地函数始终带有下划线,例如 z.add() 和 z.add_()。
# Return a new tensor z + 1
z.add(1)tensor([[ 2.2219, 2.6481],
[ 2.9546, 2.5206],
[ 2.2628, 2.6034]])# z tensor is unchanged
ztensor([[ 1.2219, 1.6481],
[ 1.9546, 1.5206],
[ 1.2628, 1.6034]])# Add 1 and update z tensor in-place
z.add_(1)tensor([[ 2.2219, 2.6481],
[ 2.9546, 2.5206],
[ 2.2628, 2.6034]])# z has been updated
ztensor([[ 2.2219, 2.6481],
[ 2.9546, 2.5206],
[ 2.2628, 2.6034]])改变形状
改变张量的形状是一个很常见的运算。首先使用 .size()获取张量的大小和形状。然后,使用 .resize_()改变张量的形状。注意下划线,改变形状是原地运算。
z.size()torch.Size([3, 2])z.resize_(2, 3)tensor([[ 2.2219, 2.6481, 2.9546],
[ 2.5206, 2.2628, 2.6034]])ztensor([[ 2.2219, 2.6481, 2.9546],
[ 2.5206, 2.2628, 2.6034]])在 Numpy 与 Torch 之间转换
在 Numpy 数组与 Torch 张量之间转换非常简单并且很实用。要通过 Numpy 数组创建张量,使用 torch.from_numpy()。要将张量转换为 Numpy 数组,使用 .numpy() 方法。
a = np.random.rand(4,3)
aarray([[ 0.57399177, 0.8398885 , 0.99316486],
[ 0.71728533, 0.116773 , 0.77742645],
[ 0.16646228, 0.34508491, 0.27752307],
[ 0.16144883, 0.26954114, 0.74938328]])b = torch.from_numpy(a)
btensor([[ 0.5740, 0.8399, 0.9932],
[ 0.7173, 0.1168, 0.7774],
[ 0.1665, 0.3451, 0.2775],
[ 0.1614, 0.2695, 0.7494]], dtype=torch.float64)b.numpy()array([[ 0.57399177, 0.8398885 , 0.99316486],
[ 0.71728533, 0.116773 , 0.77742645],
[ 0.16646228, 0.34508491, 0.27752307],
[ 0.16144883, 0.26954114, 0.74938328]])内存在 Numpy 数组与 Torch 张量之间共享,因此如果你原地更改一个对象的值,另一个对象的值也会更改。
# Multiply PyTorch Tensor by 2, in place
b.mul_(2)tensor([[ 1.1480, 1.6798, 1.9863],
[ 1.4346, 0.2335, 1.5549],
[ 0.3329, 0.6902, 0.5550],
[ 0.3229, 0.5391, 1.4988]], dtype=torch.float64)# Numpy array matches new values from Tensor
aarray([[ 1.14798353, 1.67977701, 1.98632973],
[ 1.43457067, 0.233546 , 1.55485289],
[ 0.33292455, 0.69016982, 0.55504614],
[ 0.32289765, 0.53908228, 1.49876657]])为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



