
AI For Trading:NLP pipline and text processing (79)
NLP Piplines
从任何可用形式的原始文本开始,对它进行处理,提取相关特征,建立模型,从而完成各种 NLP 任务。
常见的管道由三部分组成,文本处理、特征提取和建模。
每个阶段以特定方式转换文本,生成下一阶段所需的结果,例如,文本处理的目标是获取原始输入文本,清洗,标准化,然后将其转换成合适进行特征提取的形式,同样下一阶段需要提取和生成适用于你计划使用的模型类型,和你尝试完成NLP 任务的特征表示法。在建立这种模型时,工作流程可能不是完全线性的。

Text Processing
首先对其进行清洗,清除无关项目,例如HTML标签,然后将文本统一转换成小写,清除标点符号和多余空格,使其标准化,接下来,将文本拆分成词或令牌,清除过于常见的词,也就是停止词。

Capturing Text Data
处理阶段的第一步是读取文本数据,根据应用的不同,文本数据可能读取自多个来源。
一、本地纯文本文件读取
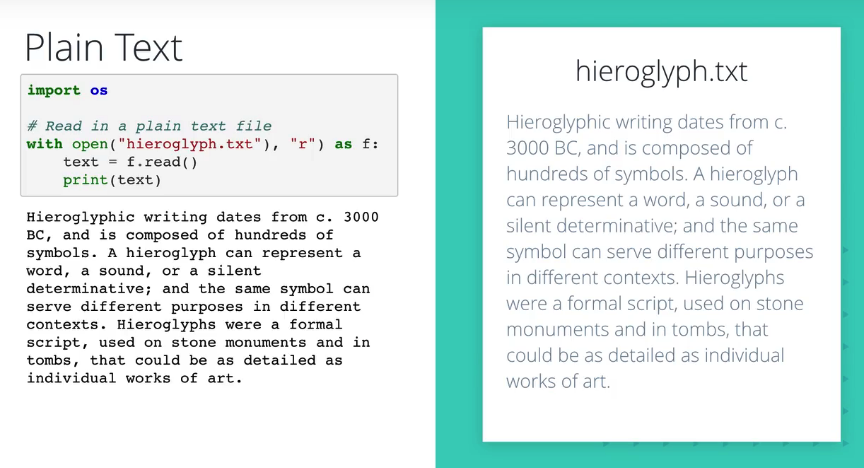
二、CSV文件读取

三、在线资源读取
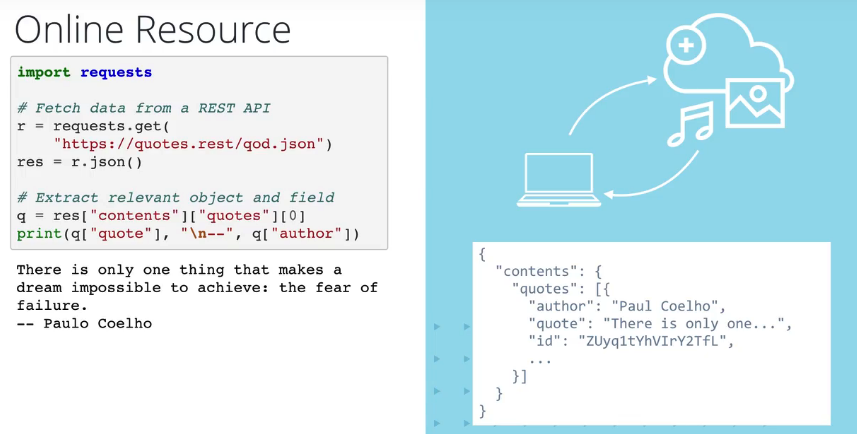
Normalization
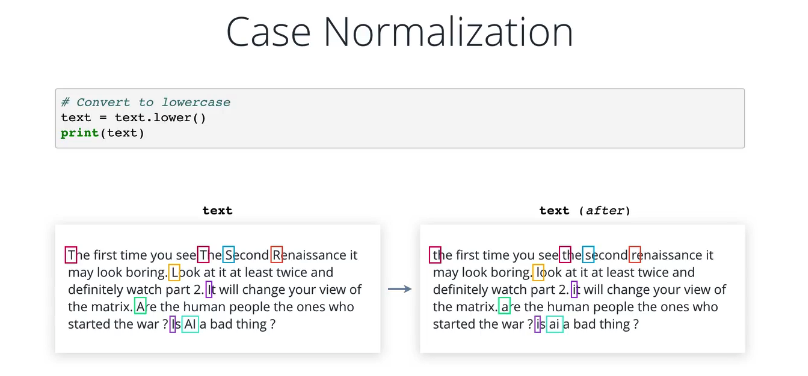
纯文本很好,但仍是含有变形和修饰物的人类语言,接下来我们将尝试降低它的复杂度,在英语语言中,所有句子开头的第一个词的首字母一般是大写的,有时全部字母大写,用于表示强调和区分风格,这对于人类读者而言非常方便,但从机器学习算法的角度来说,无法区分 car Car 和 CAR 的区别,它们都是一个意思,因此我们把词统一转换为大写或小写,一般是小写,每个词用一个唯一令牌表示。
小写转换
正则去掉标点符号
import re
# Remove punctuation characters
text = re.sub(r"[^a-zA-Z0-9]", " ", text)
print(text)

练习题:
Is it better to remove punctuation characters, or replace each with a space?
A :Remove
B:Replace with a space
答案:B,用一个空格替换特殊字符,如果直接移除则可能会和其他单词连在一起了。
Tokenization
"令牌" 是“符号”的高级表达,一般指具有某种意义,无法再分拆的符号,在自然语言处理中,令牌通常是单独的词,因此,令牌化就是将每个句子分拆成一系列词,最简单的方法是使用 split 方法,返回词列表。
# Split text into tokens(words)
words = text.split()
print(words)请注意,默认情况下在空格字符处拆分,包括普通空格、标签、新行等,这种方法还很智能,能够忽略一个序列中的两个或多个空格字符,因此不会返回空字符串,但是,你可以使用可选参数对它进行控制,目前为止,我们只使用了 Python 的内置功能,但是使用诸如如 NLTK 库,这样的一些操作就会简单许多。
NLTK 也就是“自然语言工具包(Natural Language ToolKit)” 的意思。在 NLTK 中分拆文本最常见的方法是使用 nltk.tokenize 中的 word tokenize 函数,这与split 执行的任务相同,但稍微智能了一些,在尝试传入未标准化的原始文本时,你会发现,根据标点符号位置的不同,对它们的处理也不同,头衔 Dr 后边的句号与 Dr 保留在一起,作为一个令牌,可想而知,NLTK 使用某种规则或模式决定如何处理每个标点符号。
from nltk.tokenize import word_tokenize
# split text into words using NLTK
words = word_tokenize(text)
print(words)
比如,如果你想翻译文本,可能需要将文本拆分成句子,可以通过 NLTK 使用 sent tokenize 实现这一点,然后可以根据需要将每个句子分拆成词, NLTK 提供多种令牌解析器,包括基于正则表达式的令牌解析器,可以用于进一步清除标点符号并将其令牌化,还包括推文令牌解析器,它能识别 twitter 句柄,话题标签和表情符号,
from nltk.tokenize import sent_tokenize
# split text into sentences
sents = sent_tokenize(text)
print(sents)
Reference:
nltk.tokenize package: http://www.nltk.org/api/nltk.tokenize.html
Cleaning
import requests
# Fetch a web page
r = requests.get("https://news.ycombinator.com")
print(r.text)import re
# Remove HTML tags using RegEx
pattern = re.compile(r'<.*?>') # tags look like <...>
print(pattern.sub('', r.text)) # replace them with blank使用 BeautifulSoup 库清除 HTML 标签
from bs4 import BeautifulSoup
# Remove HTML tags using Beautiful Soup library
soup = BeautifulSoup(r.text, "html5lib")
print(soup.get_text())根据样式标签找出所有相关文章
# Find all articles
summaries = soup.find_all("tr", class_="athing")
summaries[0]取出标题
# Extract title
summaries[0].find("a", class_="storylink").get_text().strip()# Find all articles, extract titles
articles = []
summaries = soup.find_all("tr", class_="athing")
for summary in summaries:
title = summary.find("a", class_="storylink").get_text().strip()
articles.append((title))
print(len(articles), "Article summaries found. Sample:")
print(articles[0])Stop word Removal
停止词是无含义的词,例如 is,our, the, in, at 等,它们不会给句子增加太多含义,停止词是非常常见的词,为了减少我们要处理的词汇量,从而降低后续程序的复杂度,需要清除停止词。
dogs are the best请注意,在上述句子中,即使没有 our 和 the, 我们仍然能推断出人对狗的正面感情。你可以自己思考下 NLTK 将英语中的那些词作为停止词,请注意,它基于特定的文本语料库或文本集,不同的语料库可能有不同的停止词。
另外,在一个应用中,一个词可能是停止词,而在另一个应用中是有用词,要从文本中清除停止词,可以使用带过滤条件的 Python 列表理解,这里,我们将影响标准化和令牌化之后,清除其中的停止词,结果有点难懂,但是请注意,输入量缩小了很多,但保留了重要词。

Part-of-Speech Tagging(词性)
Remember parts of speech from school? Nouns, pronouns,verbs,adverbs, et cetera.
还记得在学校学过的词性吗?名词,代词,动词,副词等。

识别词在句子中的用途,有助于我们更好理解句子内容,还可以明确词之间的关系,并识别出交叉引用。 NLTK 给我们带来了很多便利,你可以将词或令牌传入 POS tag 函数, 对每个词返回一个标签,并注明不同的词性。
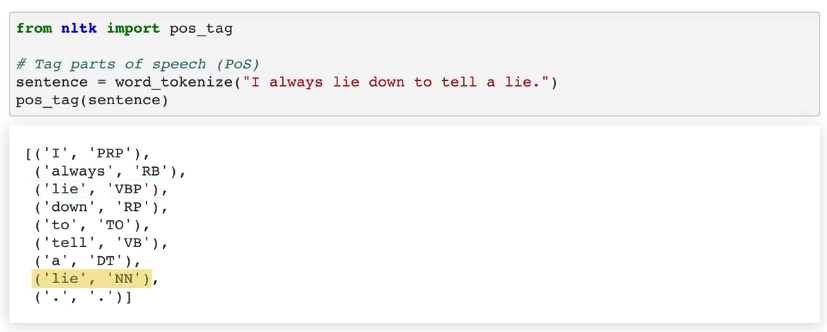
from nltk import pos_tag
# Tag parts of speech (PoS)
sentence = word_tokenize("I always lie down to tell a lie.")
pos_tag(sentence)
请注意,这个函数正确地将出现的第一个 “lie” 标注为动词,将第二个标注为名词。
自定义语法解析歧义句
自定义语法解析歧义句的一个示例,请注意解析器返回了两种有效解释,画出解析树, 更容易看出两者的区别。
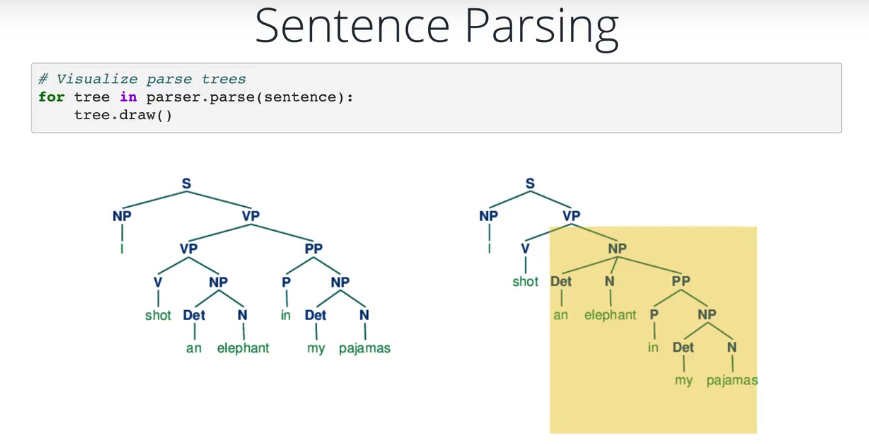
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



