
AI For Trading: Feature Extraction (84)
Intro
将文本处理成干净、标准化的形式之后,需要将其转换成可以用于建模的特征,例如,将每个文档作为一袋词,可以计算表示其特征的简单统计值,这些统计可以通过以下方式来提升效果,即通过 TF-IDF 方案分配适当权重,文档之间的比较将更准确,对于特定应用,我们可能需要找到各个词的值表示,为此,可以采用词嵌入,这是一种非常有效、强大的方法。
Bag of words(词袋)
我们学习的第一个特征表示法称为词袋,词袋模型将每个文档作为无序的词集合或词袋。在这里,文档就是你要分析的文本单位。如果你想分析每篇推文传达的感情,那么每个推文就是一个文档。
要从一段原始文本获取词袋,只需要进行合适的文本处理步骤,清洗、标准化、分拆成词、词干提取、词形还原等,然后将生成的令牌作为无序的集合。
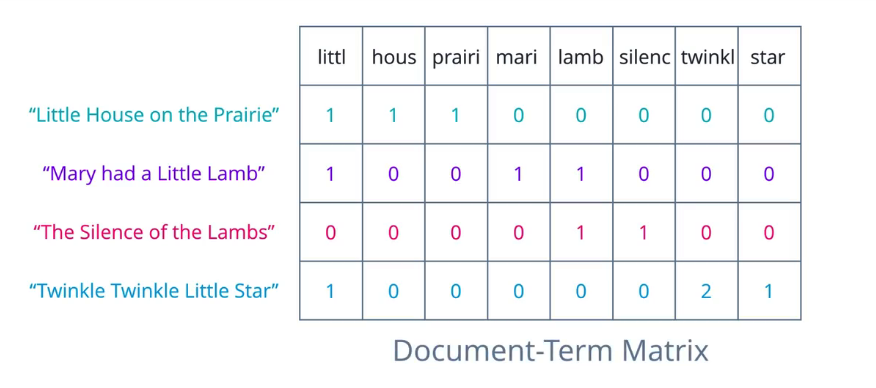
将每个文档转换成数字向量,数字向量表示的是每个词在一个文档中出现的次数,一组文档就是一个语料库,这为要向量提供了上下文,首先,将语料库中出现的所有唯一词提取出来,形成词汇表,按某种顺序排列这些词,使其形成向量元素位置或表格的列,假设每个文档是一行,然后统计每个词在每个文档中出现的次数,将值输入各列。在这一阶段为了方便起见,可以将其作为一个文档-词条矩阵。
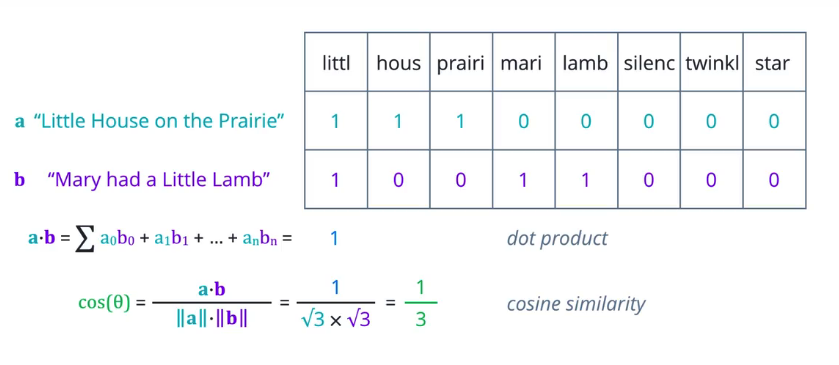
TF-IDF
词袋方法的一个限制是它将每个词的重要性同等对待,但从直觉上,我们知道在一个语料库中,某些词出现的频率比较高,例如,在财务文档中,成本或价格是非常常见的词条,为了弥补这一点,我们可以统计含有每个词的文档数量,这可以称为文档频率,然后将词频除以该词条的文档频率,由此计算的指标,与一个词条在一篇文档中出现的频率成正比,但与包含它的文档数量成反比。
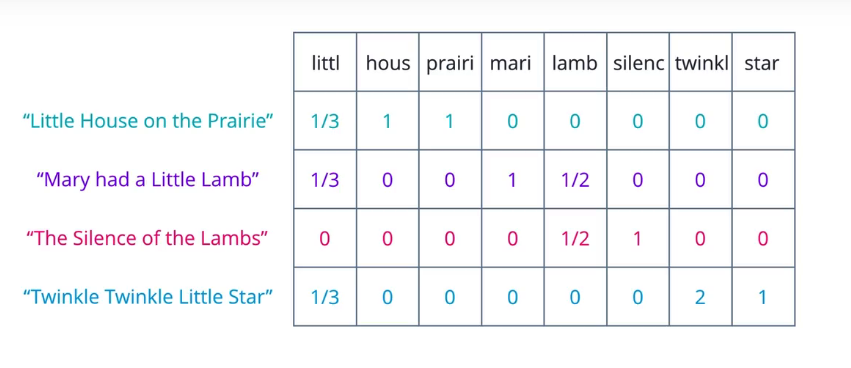
TF-IDF 是两个权重的积,公式如下:
Word2Vec
Word2Vec 可能是词嵌入在实践中应用最广泛的例子,顾名思义,是将词转换成向量,但是这个名字并没有体现出如何转换,其核心概念是一个模型能根据相邻词预测特定词,反之亦然。

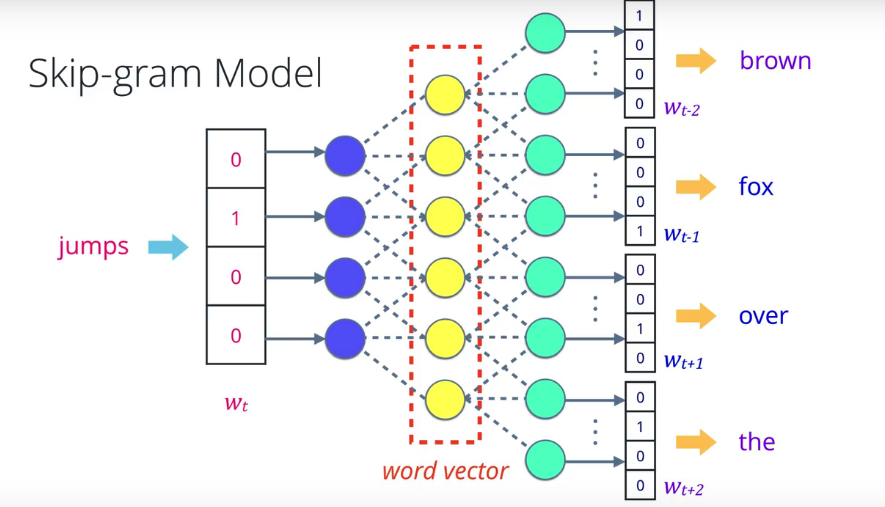
Word2Vec 模型的两种功能,一种是给出相邻词,称为连续词袋,另一种是给出中间词,称为 skip-gram, 在 skip-gram 模型中,可以从句子中挑选任何词,将其转换成 one-hot 编码向量,将其输入神经网络,或者用于预测周围词,也就是上下文的其它概率模型。
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



