
AI For Trading: BeautifulSoup Exercise and Requests Library (91)
Coding Exercise: Get Headers and Paragraphs
In the cell below, use what you learned in the previous lessons to print only the text from all the <h2> and <p> tags inside the <div> tags that have a class="section" attribute. For this quiz use the sampe.html file.
# Import BeautifulSoup
from bs4 import BeautifulSoup
# Open the HTML file and create a BeautifulSoup Object
with open('./sample.html') as f:
page_content = BeautifulSoup(f, 'lxml')
# Print only the text from all the <h2> and <p> tags inside the <div> tags that have a class="section" attribute
for section in page_content.find_all('div', class_='section'):
header = section.h2.get_text()
print(header)
paragraph = section.p.get_text()
print(paragraph)
Student Hub
Student Hub is our real time collaboration platform where you can work with peers and mentors. You will find Community rooms with other students and alumni.
Knowledge
Search or ask questions in KnowledgeThe Requests Library
Now that we know how to use BeautifulSoup to get data from HTML files, let's see how we can scrape data from a real website. Unfortunately, Beautifulsoup can't access websites directly. Therefore, in order to access websites, we will use Python's requests library. The requests library allows us to send web requests and get a website's HTML data. Once the requests library gets us the HTML data, we can use Beautifulsoup, just as we did before, to extract the data we want. So let's see an example.
In the code below we will use the requests library and BeautifulSoup to get data from the following website: https://twitter.com/AIForTrading1. This website corresponds to a Twitter account created especially for this course. This website contains 28 tweets, and our goal will be to get all these 28 tweets. To do this, we will start by importing the requests library by using:
import requestsWe will then use the requests.get(website) function to get the source code from our website. The requests.get() function returns a Response object that we will save in the variable r. We can get the HTML data we need from this object by using the .text method, as shown below:
# Import BeautifulSoup
from bs4 import BeautifulSoup
# Import requests
import requests
# Create a Response object
r = requests.get('https://twitter.com/AIForTrading1')
# Get HTML data
html_data = r.textThe .text method returns a string, therefore, html_data is a string containing the HTML data from our website. Notice, that since html_data is a string it can be passed to the BeautifulSoup constructor, and we will do this next, but for now, let's print the html_data string to see what it looks like:
# Print the HTML data
# print(html_data)As we can see, html_data indeed contains the HTML data of our website. Notice, that since we are dealing with a real website this time, the HTML file is very long.
Now that we have the HTML data from our website, we are ready to use BeautifulSoup just as we did before. The only difference is that this time, instead of passing an open filehandle to the BeautifulSoup constructor, we will pass the html_data string. So let's pass html_data to the BeautifulSoup constructor to get a BeautifulSoup object:
# Create a BeautifulSoup Object
page_content = BeautifulSoup(html_data, 'lxml')
# Print the BeautifulSoup Object
# print(page_content.prettify())Now that we have a BeautifulSoup object, we can get our tweets. To do this, we need to know which tags contain our tweets. In order to figure this out, we need to inspect our webpage using our web browser. For this example we will use the Chrome web browser but all web browsers have the same kind of functionality. We begin by going to our webpage: https://twitter.com/AIForTrading1. Next, we hover our mouse over any of the tweets. As an example we will hover over the first tweet in our webpage. Next, we right-click on the first tweet and a menu will appear. From this menu we will choose Inspect. Once we click on Inspect we will see the HTML source code of our webpage appear on the right, as shown in the figure below:
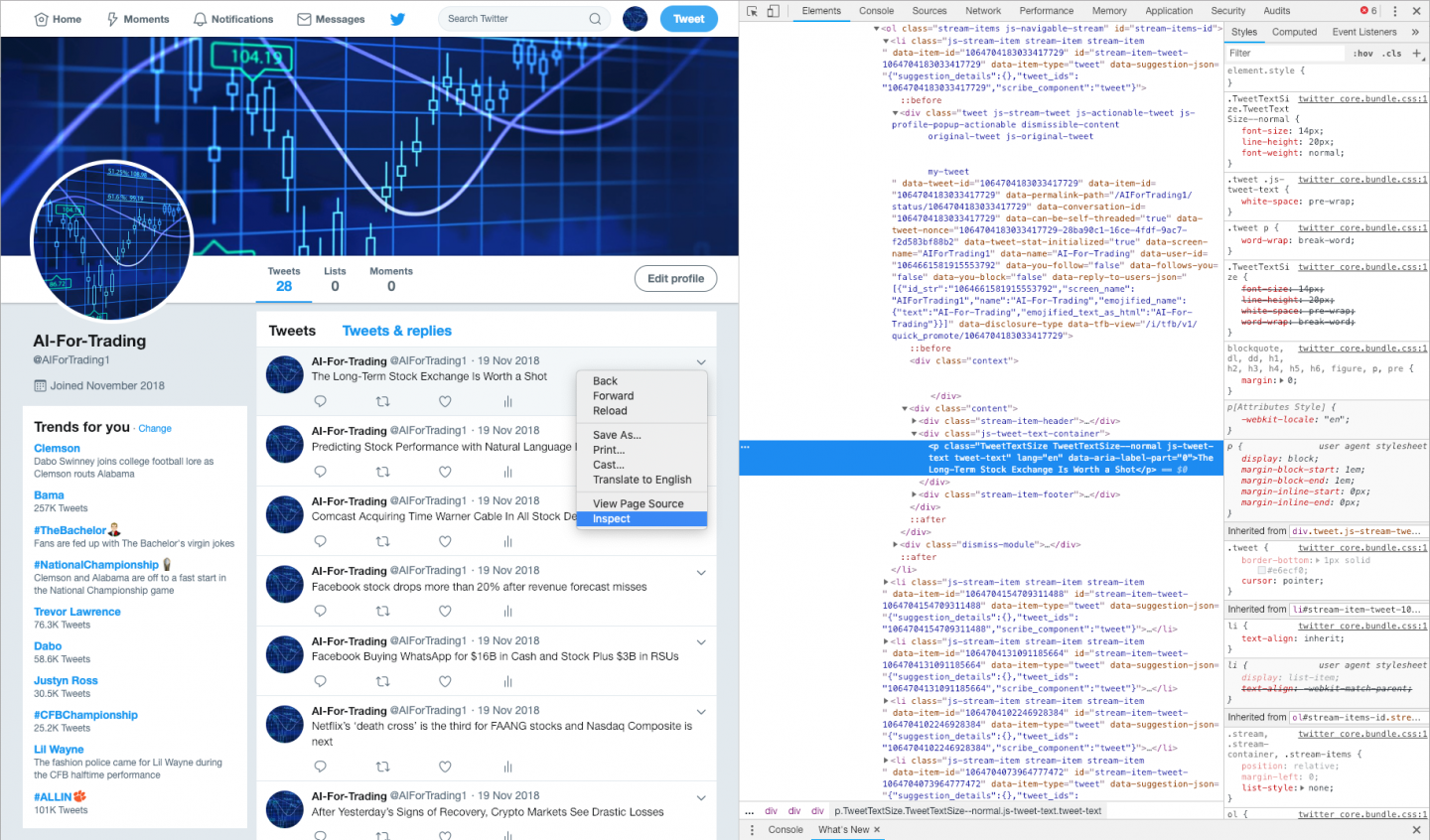
We can see that the tag where our tweet is has been highlighted in blue. We can also see that our tweet is contained within a <p> tag; and that this <p> tag is a child tag of a <div> tag with class="js-tweet-text-container", as shown below:

If we inspect the other tweets, we will see that they are all contained within the same tags. Therefore, we can use the above information to find all the tweets.
In the code below we use BeautifulSoup's find_all() method to find all the <div> tags that have class="js-tweet-text-container". We then print each tweet by accessing the <div>'s child <p> tag and using the get_text() method:
# Find all the <div> tags that have a class="js-tweet-text-container" attribute
tweets = page_content.find_all('div', class_='js-tweet-text-container')
# Set counter
counter = 1
# Print each tweet by accessing the <p> tag inside the above <div> tags using the `get_text()` method
for tweet in tweets:
print('{}. {}'.format(counter, tweet.p.get_text()))
counter += 11. The Long-Term Stock Exchange Is Worth a Shot
2. Predicting Stock Performance with Natural Language Deep Learning
3. Comcast Acquiring Time Warner Cable In All Stock Deal Worth $45.2 Billion
4. Facebook stock drops more than 20% after revenue forecast misses
5. Facebook Buying WhatsApp for $16B in Cash and Stock Plus $3B in RSUs
6. Netflix’s ‘death cross’ is the third for FAANG stocks and Nasdaq Composite is next
7. After Yesterday’s Signs of Recovery, Crypto Markets See Drastic Losses
8. MF Sees Australia Risks Tilt to Downside on China, Trade War
9. Bitcoin Cash Clash Is Costing Billions With No End in Sight
10. SEC Crypto Settlements Spur Expectations of Wider ICO Crackdown
11. Nissan’s Drama Looks a Lot Like a Palace Coup
12. Yahoo Finance has apparently killed its API
13. Tesla Tanks After Goldman Downgrades to Sell
14. Goldman Sachs to Open a Bitcoin Trading Operation
15. Tax-Free Bitcoin-To-Ether Trading in US to End Under GOP Plan
16. Goldman Sachs Is Setting Up a Cryptocurrency Trading Desk
17. Robinhood stock trading app confirms $110M raise at $1.3B valuation
18. How I made $500k with machine learning and high frequency trading
19. Tesla's Finance Team Is Losing Another Top Executive
20. Finance sites erroneously show Amazon, Apple, other stocks crashingAs we can see, we only get 20 tweets, even though our Twitter page contains a total of 28 tweets. This is because, by default, Twitter will only return 20 tweets per request. In order to get more than 20 tweets we need to use the count parameter in our web request.
The requests library allows you to provide arguments to a web request by using the params keyword argument in the .get() function. The params keyword argument consists of a dictionary of strings, with the parameters that you want. Let's see an example.
Suppose we wanted to get 50 tweets from our Twitter page https://twitter.com/AIForTrading1. To do this we need to set count=50 to our web request. This can be done by using the following code:
requests.get('https://twitter.com/AIForTrading1', params = {'count':'50'})TODO: Get All The Tweets
In the cell below, print all the 28 tweets in our Twitter page https://twitter.com/AIForTrading1. Start by importing the BeautifulSoup and requests libraries. Then use the requests.get() function with the appropriate params to get our website's HTML data. Then create a BeautifulSoup Object named page_content using our website's HTML data and the lxml parser. Then use the find_all() method to find all the <div> tags that have class="js-tweet-text-container". Then, set a counter to count each tweet. Finally, create a loop that prints all the tweets. Print the counter next to each tweet as well.
# Import BeautifulSoup
from bs4 import BeautifulSoup
# Import requests
import requests
# Get HTML data
r = requests.get('https://twitter.com/AIForTrading1', params = {'count':'28'})
html_data = r.text
# Create a BeautifulSoup Object
page_content = BeautifulSoup(html_data, 'lxml')
# Find all the <div> tags that have a class="js-tweet-text-container" attribute
tweets = page_content.find_all('div', class_='js-tweet-text-container')
counter = 1
# Print all tweets. Print the counter next to each tweet as well
for tweet in tweets:
print('{}. {}'.format(counter, tweet.p.get_text()))
counter += 11. The Long-Term Stock Exchange Is Worth a Shot
2. Predicting Stock Performance with Natural Language Deep Learning
3. Comcast Acquiring Time Warner Cable In All Stock Deal Worth $45.2 Billion
4. Facebook stock drops more than 20% after revenue forecast misses
5. Facebook Buying WhatsApp for $16B in Cash and Stock Plus $3B in RSUs
6. Netflix’s ‘death cross’ is the third for FAANG stocks and Nasdaq Composite is next
7. After Yesterday’s Signs of Recovery, Crypto Markets See Drastic Losses
8. MF Sees Australia Risks Tilt to Downside on China, Trade War
9. Bitcoin Cash Clash Is Costing Billions With No End in Sight
10. SEC Crypto Settlements Spur Expectations of Wider ICO Crackdown
11. Nissan’s Drama Looks a Lot Like a Palace Coup
12. Yahoo Finance has apparently killed its API
13. Tesla Tanks After Goldman Downgrades to Sell
14. Goldman Sachs to Open a Bitcoin Trading Operation
15. Tax-Free Bitcoin-To-Ether Trading in US to End Under GOP Plan
16. Goldman Sachs Is Setting Up a Cryptocurrency Trading Desk
17. Robinhood stock trading app confirms $110M raise at $1.3B valuation
18. How I made $500k with machine learning and high frequency trading
19. Tesla's Finance Team Is Losing Another Top Executive
20. Finance sites erroneously show Amazon, Apple, other stocks crashing
21. Jeff Bezos Says He Is Selling $1 Billion a Year in Amazon Stock to Finance Race to Space
22. US government commits to publish publicly financed software under Free Software licenses
23. The dream life is having your luggage first out of the carousel each time.
24. Stocks Sink as Apple, Facebook Pace the Tech Wreck: Markets Wrap
25. Elon Musk's SpaceX Cuts Loan Deal by $500 Million
26. Nvidia Stock Falls Another 12%
27. Anything is possible in this world! Exhibit A: Creation of a sequel to Superbabies.
28. Elon Musk forced to step down as chairman, TSLA short all the way!XML
Throughout these lessons we have used HTML files to show you how to scrape data. We should note that the exact same techniques can be applied to XML files. The only difference is that you will have to use an XML parser in the BeautifulSoup constructor. For example, in order to parse a document as XML, you can use lxml’s XML parser by passing in xml as the second argument to the BeautifulSoup constructor:
page_content = BeautifulSoup(xml_file, 'xml')The above statement will parse the given xml_file as XML using the xml parser.
Final Remarks
So now you should know how to scrape data from websites using the requests and BeautifulSoup libraries. We should note, that you should be careful when scrapping websites not to overwhelm a website's server. This can happen if you write computer programs that send out a lot of requests very quickly. Doing this, will overwhelm the server and probably cause it to get stuck. This is obviously very bad, so avoid making tons of web requests in a short amount of time. In fact, some servers monitor if you are making too many requests and block you, if you are doing so. So keep this in mind when you are writing computer programs.
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


