
AI For Trading:TF-IDF (93)
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。
TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
So naturally it would be useful to reduce the importance of frequent words in our bag of words. This can be done through the re-weighing method called term frequency inverse document frequency.

Similarity Metrics
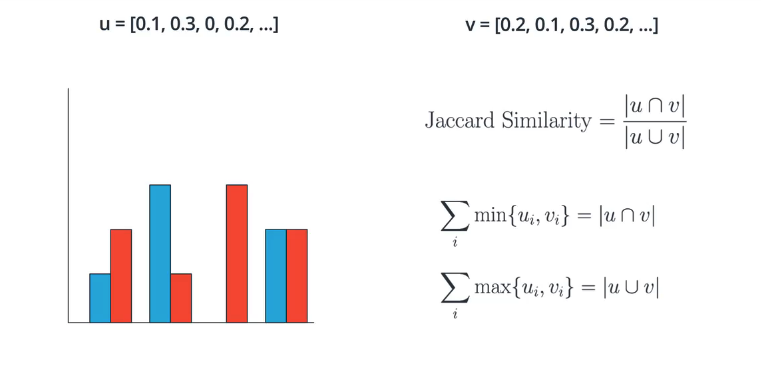
Part 1: Bag-of-Words Exercises
In the following, we will convert our corpus of 10-k documents into bag-of-words, and convert them into document vectors using Term-Frequency-Inverse-Document-Frequency (tf-idf) re-weighting. Afterward, we will compute sentiments and similarity metrics. Since we will be reusing our notebook, so the various sections are linked below:
-
Compute bag-of-words : implement
bag_of_wordsthat converts tokenized words into a dictionary of word-counts -
Sentiments : using wordlists, compute positive and negative sentiments from bag-of-words. Implement
get_sentiment
For solutions, see bagofwords_solutions.py. You can load the functions by simply calling
from bagofwords_solutions import *
Part 2: Document-Vector Exercises
-
Compute idf : computing the inverse document frequency, implement
get_idf -
Compute tf : computing the term frequency, implement
get_tf -
Document vector : using the functions
get_idfandget_tf, compute a word_vector for each document in the corpus -
Similarities : comparing two vectors, and compute cosine and jacard similarity metrics. Implement
get_cosandget_jac
For solutions, see bagofwords_solutions.py. You can load the functions by simply calling
from bagofwords_solutions import *
0. Initialization
First we read in our 10-k documents
# download some excerpts from 10-K files
from download10k import get_files
CIK = {'ebay': '0001065088', 'apple':'0000320193', 'sears': '0001310067'}
get_files(CIK['ebay'], 'EBAY')
get_files(CIK['apple'], 'AAPL')
get_files(CIK['sears'], 'SHLDQ')
# get a list of all 10-ks in our directory
files=! ls *10k*.txt
print("10-k files: ",files)
files = [open(f,"r").read() for f in files]downloading 10-Ks item 1A for CIK = 0001065088 ...
skipping EBAY_10k_2017.txt
skipping EBAY_10k_2016.txt
skipping EBAY_10k_2015.txt
skipping EBAY_10k_2014.txt
skipping EBAY_10k_2013.txt
downloading 10-Ks item 1A for CIK = 0000320193 ...
skipping AAPL_10k_2017.txt
skipping AAPL_10k_2016.txt
skipping AAPL_10k_2015.txt
skipping AAPL_10k_2014.txt
skipping AAPL_10k_2013.txt
downloading 10-Ks item 1A for CIK = 0001310067 ...
skipping SHLDQ_10k_2017.txt
skipping SHLDQ_10k_2016.txt
skipping SHLDQ_10k_2015.txt
skipping SHLDQ_10k_2014.txt
skipping SHLDQ_10k_2013.txt
10-k files: ['AAPL_10k_2013.txt', 'AAPL_10k_2014.txt', 'AAPL_10k_2015.txt', 'AAPL_10k_2016.txt', 'AAPL_10k_2017.txt', 'EBAY_10k_2013.txt', 'EBAY_10k_2014.txt', 'EBAY_10k_2015.txt', 'EBAY_10k_2016.txt', 'EBAY_10k_2017.txt', 'SHLDQ_10k_2013.txt', 'SHLDQ_10k_2014.txt', 'SHLDQ_10k_2015.txt', 'SHLDQ_10k_2016.txt', 'SHLDQ_10k_2017.txt']here we define useful functions to tokenize the texts into words, remove stop-words, and lemmatize and stem our words
import numpy as np
# for nice number printing
np.set_printoptions(precision=3, suppress=True)
# tokenize and clean the text
import nltk
from nltk.stem import WordNetLemmatizer, SnowballStemmer
from collections import Counter
from nltk.corpus import stopwords
from nltk import word_tokenize
from nltk.tokenize import RegexpTokenizer
# tokenize anything that is not a number and not a symbol
word_tokenizer = RegexpTokenizer(r'[^\d\W]+')
nltk.download('stopwords')
nltk.download('wordnet')
sno = SnowballStemmer('english')
wnl = WordNetLemmatizer()
# get our list of stop_words
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
# add some extra stopwords
stop_words |= {"may", "business", "company", "could", "service", "result", "product",
"operation", "include", "law", "tax", "change", "financial", "require",
"cost", "market", "also", "user", "plan", "actual", "cash", "other",
"thereto", "thereof", "therefore"}
# useful function to print a dictionary sorted by value (largest first by default)
def print_sorted(d, ascending=False):
factor = 1 if ascending else -1
sorted_list = sorted(d.items(), key=lambda v: factor*v[1])
for i, v in sorted_list:
print("{}: {:.3f}".format(i, v))
# convert text into bag-of-words
def clean_text(txt):
lemm_txt = [ wnl.lemmatize(wnl.lemmatize(w.lower(),'n'),'v') \
for w in word_tokenizer.tokenize(txt) if \
w.isalpha() and w not in stop_words ]
return [ sno.stem(w) for w in lemm_txt if w not in stop_words and len(w) > 2 ]
corpus = [clean_text(f) for f in files][nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
[nltk_data] Downloading package wordnet to /root/nltk_data...
[nltk_data] Unzipping corpora/wordnet.zip.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Package stopwords is already up-to-date!1. Bag-of-Words
Implement a function that converts a list of tokenized words into bag-of-words, i.e. a dictionary that outputs the frequency count of a word
** python already provide the collections.Counter class to perform this, but I encourage you to implement your own function as an exercise
from collections import defaultdict
def bag_of_words(words):
bag = defaultdict(int)
for w in words:
bag[w] += 1
return bag
2. Sentiments
Count the fraction of words that appear in a wordlist, returning a sentiment score between 0 and 1:
$$
\textrm{score} = \frac{\textrm{Number of words in document matching wordlist}}{\textrm{Number of words in document}}
$$
Implement the score in a function get_sentiment(words, wordlist), where words is a list of words. Feel free to use the previous bag_of_words function.
(for extra challenge, try to code the function in one-line)
Here, I've included a positive and negative wordlist that I constructed by hand. Due to copyright issues, we are not able to provide other commonly used wordlists. I encourage you to try out different wordlists on your own.
# load wordlist first
import pickle
with open('positive_words.pickle', 'rb') as f:
positive_words = pickle.load(f)
# also need to stem and lemmatize the text
positive_words = set(clean_text(" ".join(positive_words)))
with open('negative_words.pickle', 'rb') as f:
negative_words = pickle.load(f)
negative_words = set(clean_text(" ".join(negative_words)))
# check out the list
print("positive words: ", positive_words)
print("negative words: ", negative_words)positive words: {'devot', 'effect', 'happili', 'reliev', 'persever', 'abund', 'wow', 'fortun', 'bless', 'resolv', 'champion', 'great', 'booster', 'virtuous', 'enrich', 'lead', 'loyal', 'trendili', 'incred', 'invent', 'jubil', 'extraordinari', 'endors', 'stabil', 'surmount', 'fabul', 'distinguish', 'eleg', 'meritori', 'compliment', 'magic', 'creativ', 'support', 'terrif', 'pleasant', 'solv', 'courag', 'award', 'aptitud', 'generous', 'complet', 'best', 'congratul', 'perfect', 'appeal', 'delight', 'advanc', 'relief', 'exhilar', 'appreci', 'glamor', 'high', 'optimist', 'boon', 'accomplish', 'good', 'harmoni', 'tremend', 'safe', 'love', 'attain', 'resourc', 'winner', 'strong', 'glow', 'applaus', 'divin', 'admir', 'revolutionari', 'famous', 'superb', 'stupend', 'outstand', 'earnest', 'clean', 'distinct', 'talent', 'victori', 'impress', 'legendari', 'revolut', 'popular', 'bliss', 'fresh', 'master', 'success', 'win', 'excel', 'effici', 'enhanc', 'approv', 'belov', 'inspir', 'enthusiasm', 'nobl', 'gift', 'wealthi', 'except', 'satisfactori', 'enchant', 'improv', 'refresh', 'stabl', 'upstand', 'promin', 'lucrat', 'fantast', 'rebound', 'surpass', 'exquisit', 'benevol', 'wholesom', 'benefit', 'buoy', 'clear', 'satisfi', 'vibrant', 'spring', 'loyalti', 'paradis', 'succeed', 'gain', 'independ', 'acclaim', 'happi', 'reinforc', 'wealth', 'outperform', 'miracul', 'flawless', 'favor', 'bright', 'rich', 'flourish', 'amaz', 'higher', 'celebr', 'progress', 'surg', 'visionari', 'benign', 'monument', 'prais', 'honor', 'attract', 'accept', 'innov', 'encourag', 'respect', 'nurtur', 'growth', 'polish', 'exuber', 'recoveri', 'ador', 'transform', 'special', 'extraordinarili', 'nobil', 'upbeat', 'passion', 'groundbreak', 'motiv', 'better', 'miracl', 'achiev', 'power', 'wonder', 'dynam', 'recov', 'dazzl', 'ingeni', 'exemplifi', 'reward', 'astonish', 'adorn', 'actual', 'brighter', 'boost', 'profici', 'brilliant', 'revolution', 'posit', 'bolster', 'esteem', 'plenti', 'restor', 'beauti', 'benefici', 'marvel', 'solut', 'heal', 'prestig', 'cheer', 'optim', 'command', 'prosper', 'fascin', 'strength', 'elev', 'origin', 'prodigi', 'nourish', 'forefront', 'laud', 'nobli', 'opportun', 'prestigi', 'product', 'trendi', 'amelior', 'insight', 'awesom', 'merit', 'championship'}
negative words: {'inviabl', 'suspici', 'attrit', 'fail', 'sacrific', 'hate', 'disinterest', 'repuls', 'nasti', 'offens', 'dread', 'fraudul', 'inconveni', 'burden', 'crash', 'outlaw', 'penalti', 'shame', 'recal', 'uneffect', 'crime', 'harrow', 'scorn', 'counterfeit', 'disqualif', 'blow', 'untrustworthi', 'close', 'depress', 'hostil', 'eros', 'difficult', 'inferior', 'misus', 'storm', 'desist', 'repugn', 'accus', 'erod', 'refus', 'weari', 'malign', 'ruin', 'apathet', 'strain', 'crisi', 'disfavor', 'dirtili', 'nullifi', 'horror', 'collus', 'blacklist', 'abhor', 'degrad', 'terribl', 'gruesom', 'wors', 'violent', 'breach', 'usurp', 'hatr', 'death', 'unnecessari', 'hamper', 'pessimist', 'harsher', 'discourag', 'pollut', 'harsh', 'damag', 'imposs', 'neglect', 'cutback', 'argument', 'default', 'temper', 'instabl', 'turbul', 'dark', 'illeg', 'dismal', 'dysfunct', 'gloomi', 'wick', 'illiquid', 'suspend', 'disregard', 'exploit', 'downgrad', 'calam', 'deris', 'imperil', 'destroy', 'drain', 'collud', 'desper', 'blackmail', 'tragic', 'arrest', 'flaw', 'distress', 'ineffect', 'low', 'excess', 'nefari', 'imped', 'disabl', 'balk', 'declin', 'uneth', 'disast', 'crack', 'hardest', 'lie', 'sever', 'unworthi', 'deprav', 'murder', 'subpoena', 'underperform', 'objection', 'escal', 'doomsday', 'mockeri', 'terror', 'unfruit', 'plung', 'retreat', 'unfortun', 'devalu', 'indign', 'headach', 'notori', 'argu', 'hardship', 'null', 'desol', 'sue', 'avoid', 'investig', 'debt', 'rot', 'shutdown', 'frustrat', 'worsen', 'unscrupul', 'worri', 'dirti', 'antiqu', 'boycott', 'apathi', 'vilifi', 'atroci', 'abomin', 'wast', 'accid', 'steal', 'weaken', 'pressur', 'hinder', 'unwelcom', 'obstruct', 'disapprov', 'fear', 'unproduct', 'blame', 'weak', 'pessim', 'unattract', 'overpay', 'convict', 'fraud', 'indict', 'loot', 'bust', 'catastroph', 'falsifi', 'troublesom', 'discredit', 'negat', 'trial', 'trivial', 'unneed', 'uninspir', 'afflict', 'conflict', 'untal', 'conced', 'cataclysm', 'aggrav', 'impoverish', 'harm', 'lawsuit', 'uncontrol', 'diminish', 'fiasco', 'deplor', 'misappl', 'unpopular', 'deterior', 'complic', 'disadvantag', 'doom', 'failur', 'hurt', 'suspens', 'empti', 'delay', 'error', 'disturb', 'complaint', 'worrisom', 'contradict', 'halt', 'erron', 'vulgar', 'ugli', 'insol', 'fatal', 'rotten', 'unabl', 'incap', 'advers', 'faulti', 'worst', 'foul', 'deplet', 'disqualifi', 'devast', 'lazi', 'sorrow', 'injuri', 'unlaw', 'unsettl', 'disgust', 'renounc', 'taint', 'defianc', 'harder', 'insan', 'guilt', 'fright', 'ceas', 'impeach', 'postpon', 'inabl', 'strike', 'insolv', 'unfair', 'revolt', 'corrupt', 'anomali', 'misappli', 'aw', 'closur', 'disclaim', 'repudi', 'intimid', 'stress', 'fire', 'malfunct', 'curs', 'deni', 'evil', 'vice', 'malic', 'misfortun', 'underwhelm', 'ineffici', 'embezzl', 'violat', 'perjuri', 'exacerb', 'shadi', 'abhorr', 'leak', 'inept', 'exhaust', 'thieveri', 'distast', 'nuisanc', 'horrid', 'scourg', 'hazard', 'obsolet', 'gloom', 'obsolesc', 'termin', 'critic', 'dissolv', 'ridicul', 'woe', 'slow', 'demot', 'guilti', 'thiev', 'agoni', 'bribe', 'handicap', 'invalid', 'lack', 'manipul', 'unauthor', 'confus', 'lazili', 'dampen', 'kill', 'cloudi', 'difficulti', 'fals', 'defiant', 'lag', 'attenu', 'bankruptci', 'scandal', 'horrend', 'obnoxi', 'unfavor', 'danger', 'content', 'ban', 'object', 'undermin', 'bottleneck', 'decept', 'break', 'miseri', 'litig', 'breakabl', 'appal', 'illicit', 'accident', 'nastili', 'horribl', 'incident', 'wrong', 'troubl', 'jail', 'forfeit', 'impedi', 'abnorm', 'contempt', 'doubt', 'injur', 'wreck', 'lower', 'tragedi', 'incompat', 'condemn', 'deter', 'odious', 'forgeri', 'sacrifici', 'bankrupt', 'delus', 'urgent', 'fault', 'unattain', 'fruitless', 'dead', 'dull', 'powerless', 'incid', 'threat', 'impot', 'oppress', 'hard', 'vile', 'unstabl', 'unhappi', 'peril', 'reject', 'unnecessarili', 'abandon', 'plea', 'shrink', 'upset', 'panic'}def get_sentiment(txt, wordlist):
matching_words = [w for w in txt if w in wordlist]
return len(matching_words)/len(txt)# test your function
positive_sentiments = np.array([ get_sentiment(c, positive_words) for c in corpus ])
print(positive_sentiments)
negative_sentiments = np.array([ get_sentiment(c, negative_words) for c in corpus ])
print(negative_sentiments)[ 0.034 0.033 0.032 0.032 0.031 0.034 0.033 0.034 0.031 0.032
0.037 0.033 0.037 0.039 0.04 ]
[ 0.054 0.053 0.052 0.052 0.053 0.051 0.05 0.054 0.061 0.061
0.06 0.059 0.058 0.054 0.059]before continuing part 2, go through the lesson material first!
Part 2 Document Vector Exercises
3. Computer idf
Given a corpus, or a list of bag-of-words, we want to compute for each word $w$, the inverse-document-frequency, or ${\rm idf}(w)$. This can be done in a few steps:
-
Gather a set of all the words in all the bag-of-words (python set comes in handy, and the union operator
|is useful here) -
Loop over each word $w$, and compute ${\rm df}_w$, the number of documents where this word appears at least once. A dictionary is useful for keeping track of ${\rm df}_w$
-
After computing ${\rm df}_w$, we can compute ${\rm idf}(w)$. There are usually two possibilities, the simplest one is
$${\rm idf}(w)=\frac{N}{{\rm df}_w}$$
Where $N$ is the total number of documents in the corpus and $df_w$ the number of documents that contain the word $w$. Frequently, a logarithm term is added as well
$${\rm idf}(w)=\log\frac{N}{{\rm df}_w}$$
One issue with using the logarithm is that when ${\rm df}_w = N$, ${\rm idf}(w)=0$, indicating that words common to all documents would be ignored. If we don't want this behavior, we can define ${\rm idf}(w)=\log\left(1+N/{\rm df}_w\right)$ or ${\rm idf}(w)=1+\log\left(N/{\rm df}_w\right)$ instead. For us, we'll not use the extra +1 for ${\rm idf}$.
In the following, define a function called get_idf(corpus, include_log=True) that computes ${\rm idf}(w)$ for all the words in a corpus, where corpus for us is a processed list of bag-of-words (stemmed and lemmatized). The optional parameter include_log includes the logarithm in the computation.
# compute idf
from math import log
def get_idf(corpus, include_log=True):
N = len(corpus)
freq = defaultdict(int)
words = set()
for c in corpus:
words |= set(c)
for w in words:
freq[w] = sum([ w in c for c in corpus])
if include_log:
return { w:log(N/freq[w]) for w in freq }
else:
return { w:N/freq[w] for w in freq }You should expect to see many idf values = 0! This is by design, because we have ${\rm idf}(w)=\log N_d/{\rm df}_w$ and $N_d/{\rm df}_w=1$ for the most common words!
# test your code
idf=get_idf(corpus)
print_sorted(idf, ascending=True)identifi: 0.000
thus: 0.000
accord: 0.000
materi: 0.000
direct: 0.000
seek: 0.000
across: 0.000
cashedg: 2.7084. Compute tf
Below we will compute ${\rm tf}(w,d)$, or the term frequency for a given word $w$, in a given document $d$. Since our ultimate goal is to compute a document vector, we'd like to keep a few things in mind
- Store the ${\rm tf}(w, d)$ for each word in a document as a dictionary
- Even when a word doesn't appear in the document $d$, we still want to keep a $0$ entry in the dictionary. This is important when we convert the dictionary to a vector, where zero entries are important
There are multiple definitions for ${\rm tf}(w,d)$, the simplest one is
$$
{\rm tf}(w,d)=\frac{f_{w,d}}{a_d}
$$
where $f_{w,d}$ is the number of occurence of the word $w$ in the document $d$, and $a$ the average occurence of all the words in that document for normalization. Just like ${\rm idf}(w)$, a logarithm can be added
$$
{\rm tf}(w,d)=\begin{cases}
\frac{1+\log f_{w,d}}{1+\log ad} & f{w,d} > 0 \
0 & f_{w,d} = 0 \
\end{cases}
$$
Implement the function get_df(txt, include_log=True) that computes ${\rm tf}(w,d)$ for each word in the document (returns a defaultdict(int), so that when supplying words not in the document the dictionary will yield zero instead of an error). Also include the optional parameter include_log that enables the additional logarithm term in the computation. I suggest also adding a function called _tf that computes the function above.
import numpy as np
from math import *
def _tf(freq, avg, include_log=True):
if include_log:
return 0 if freq == 0 else (1+log(freq))/(1+log(avg))
else:
return freq/avg
def get_tf(txt, include_log=True):
freq = bag_of_words(txt)
avg = np.mean(list(freq.values()))
tf = {w:_tf(f,avg, include_log) for w,f in freq.items()}
return defaultdict(int, tf)
tfs = [ get_tf(c) for c in corpus ]
print_sorted(tfs[0])signific: 1.920
compon: 1.920
risk: 1.855
develop: 1.855
affect: 1.841
price: 1.841
adequaci: 0.4225. Document Vector
Combine the implementation for ${\rm tf}(w,d)$ and ${\rm idf}(w)$ to compute a word-vector for each document in a corpus. Don't forget the zero-padding that is needed when a word appears in some document but not others.
Implmenet the function get_vectors(tf,idf), the input is the output computed by get_tf and get_idf
(optional challenge: implement in one line!)
def get_vector(tf, idf):
return np.array([ tf[w]*idf[w] for w in idf ])# test your code
doc_vectors = [ get_vector(tf, idf) for tf in tfs ]
for v in doc_vectors:
print(v)[ 0. 0. 0. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 0. 0. 0.26]
[ 0. 0. 0. ..., 0. 0. 0.26]
[ 0. 0. 0. ..., 0. 0. 0.26]
[ 0.339 0. 0.497 ..., 0. 1.415 0.463]
[ 0.559 0. 0.484 ..., 0. 0. 0.451]
[ 0. 0. 0.522 ..., 0. 0. 0.428]
[ 0. 0. 0. ..., 0. 0. 0.478]
[ 0. 0. 0. ..., 0. 0. 0.473]
[ 0. 0. 0. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 0. 0. 0.]
[ 0.5 0. 0. ..., 0. 0. 0. ]
[ 0.486 0.891 0. ..., 0. 0. 0. ]
[ 0.456 0.836 0. ..., 1.124 0. 0. ]6. Similarity
Given two word-vectors $\vec u$ (or $u_i$) and $\vec v$ (or $v_i$), corresponding to two documents, we want to compute different similarity metrics.
-
Cosine similarity, defined by
$$
{\rm Sim}_{\cos} = \frac{\vec u \cdot \vec v}{|\vec u| |\vec v|}
$$ -
Jaccard similarity, defined by
$$
{\rm Sim}_{\rm Jaccard} = \frac{\sum_i \min{u_i, v_i}}{\sum_i \max{u_i, v_i}}
$$
Implement the function similarity as sim_cis(u,v) and sim_jac(u,v). Utilize the numpy functions numpy.linalg.norm to compute norm of a vector and np.dot for computing dot-products. np.minimum and np.maximum are also useful vectorized pair-wise minimum and maximum functions.
(optional challenge: implement both functions in one line!)
from numpy.linalg import norm
def sim_cos(u,v):
return np.dot(u,v)/(norm(u)*norm(v))
def sim_jac(u,v):
return np.sum(np.minimum(u,v))/np.sum(np.maximum(u,v))# test your co
# compute all the pairwise similarity metrics
size = len(doc_vectors)
matrix_cos = np.zeros((size,size))
matrix_jac = np.zeros((size,size))
for i in range(size):
for j in range(size):
u = doc_vectors[i]
v = doc_vectors[j]
matrix_cos[i][j] = sim_cos(u,v)
matrix_jac[i][j] = sim_jac(u,v)
print("Cosine Similarity:")
print(matrix_cos)
print()
print("Jaccard Similarity:")
print(matrix_jac)Cosine Similarity:
[[ 1. 0.95 0.912 0.903 0.89 0.122 0.12 0.136 0.135 0.139
0.017 0.025 0.03 0.041 0.074]
[ 0.95 1. 0.961 0.947 0.932 0.116 0.114 0.132 0.127 0.13
0.017 0.024 0.03 0.041 0.071]
[ 0.912 0.961 1. 0.986 0.931 0.122 0.121 0.139 0.133 0.137
0.017 0.024 0.032 0.041 0.074]
[ 0.903 0.947 0.986 1. 0.941 0.124 0.123 0.138 0.135 0.141
0.018 0.025 0.033 0.043 0.076]
[ 0.89 0.932 0.931 0.941 1. 0.121 0.12 0.136 0.134 0.137
0.021 0.027 0.035 0.044 0.073]
[ 0.122 0.116 0.122 0.124 0.121 1. 0.893 0.591 0.469 0.473
0.061 0.078 0.115 0.126 0.145]
[ 0.12 0.114 0.121 0.123 0.12 0.893 1. 0.601 0.452 0.455
0.059 0.072 0.107 0.119 0.142]
[ 0.136 0.132 0.139 0.138 0.136 0.591 0.601 1. 0.654 0.661
0.069 0.083 0.116 0.126 0.147]
[ 0.135 0.127 0.133 0.135 0.134 0.469 0.452 0.654 1. 0.954
0.071 0.084 0.095 0.101 0.133]
[ 0.139 0.13 0.137 0.141 0.137 0.473 0.455 0.661 0.954 1. 0.074
0.087 0.098 0.102 0.135]
[ 0.017 0.017 0.017 0.018 0.021 0.061 0.059 0.069 0.071 0.074 1.
0.843 0.558 0.435 0.354]
[ 0.025 0.024 0.024 0.025 0.027 0.078 0.072 0.083 0.084 0.087
0.843 1. 0.602 0.482 0.387]
[ 0.03 0.03 0.032 0.033 0.035 0.115 0.107 0.116 0.095 0.098
0.558 0.602 1. 0.719 0.507]
[ 0.041 0.041 0.041 0.043 0.044 0.126 0.119 0.126 0.101 0.102
0.435 0.482 0.719 1. 0.672]
[ 0.074 0.071 0.074 0.076 0.073 0.145 0.142 0.147 0.133 0.135
0.354 0.387 0.507 0.672 1. ]]
Jaccard Similarity:
[[ 1. 0.901 0.836 0.825 0.803 0.069 0.066 0.094 0.11 0.111
0.018 0.028 0.045 0.055 0.075]
[ 0.901 1. 0.918 0.9 0.88 0.069 0.066 0.095 0.108 0.11
0.019 0.029 0.046 0.055 0.075]
[ 0.836 0.918 1. 0.977 0.892 0.073 0.07 0.1 0.113 0.114
0.02 0.029 0.048 0.056 0.078]
[ 0.825 0.9 0.977 1. 0.904 0.073 0.07 0.099 0.114 0.116
0.02 0.03 0.049 0.057 0.079]
[ 0.803 0.88 0.892 0.904 1. 0.072 0.069 0.099 0.113 0.114
0.022 0.032 0.05 0.059 0.079]
[ 0.069 0.069 0.073 0.073 0.072 1. 0.795 0.419 0.287 0.287
0.026 0.035 0.062 0.077 0.1 ]
[ 0.066 0.066 0.07 0.07 0.069 0.795 1. 0.418 0.271 0.271
0.024 0.033 0.056 0.071 0.095]
[ 0.094 0.095 0.1 0.099 0.099 0.419 0.418 1. 0.497 0.499
0.035 0.046 0.075 0.091 0.116]
[ 0.11 0.108 0.113 0.114 0.113 0.287 0.271 0.497 1. 0.927
0.04 0.052 0.076 0.088 0.114]
[ 0.111 0.11 0.114 0.116 0.114 0.287 0.271 0.499 0.927 1. 0.042
0.054 0.078 0.089 0.116]
[ 0.018 0.019 0.02 0.02 0.022 0.026 0.024 0.035 0.04 0.042 1.
0.701 0.367 0.266 0.189]
[ 0.028 0.029 0.029 0.03 0.032 0.035 0.033 0.046 0.052 0.054
0.701 1. 0.46 0.342 0.24 ]
[ 0.045 0.046 0.048 0.049 0.05 0.062 0.056 0.075 0.076 0.078
0.367 0.46 1. 0.621 0.397]
[ 0.055 0.055 0.056 0.057 0.059 0.077 0.071 0.091 0.088 0.089
0.266 0.342 0.621 1. 0.54 ]
[ 0.075 0.075 0.078 0.079 0.079 0.1 0.095 0.116 0.114 0.116
0.189 0.24 0.397 0.54 1. ]]Good Job! You've finished all the exercises!
Here is an optional bonus challenge. We often need to debug other people's code to figure out what's wrong. It's particularly difficult when the code doesn't give errors but computes the wrong quantity. Can you describe why the following implementations for some of the exercises above may be wrong? Highlight the words at the bottom to reveal the solutions!
def get_idf_wrong(corpus, include_log=True):
freq = defaultdict(int)
for c in corpus:
for w in c:
freq[w] += 1
N = len(corpus)
if include_log:
return { w:log(N/freq[w]) for w in freq }
else:
return { w:N/freq[w] for w in freq }
def get_sentiment_wrong(txt, wordlist):
matching_words = [ w for w in wordlist if w in txt ]
return len(matching_words)/len(txt)
def get_vectors_wrong(tf, idf):
return np.array([ tf[w]*idf[w] for w in tf ])Solutions
Drag your mouse over the white space below this cell, and you'll see details about the solutions. Or, if it's easier, just double-click on the white space below this cell, which will reveal the cell with hidden text.
Solution
get_idf: the defaultdict freq here computes the total number of occurences in all the document. We only want to count it once when a word appears in a document. This may lead to a document frequency larger than N, leading to a negative idf!
get_sentiment_wrong: if a word w appears twice in the document, it won't be counted properly!
get_vectors_wrong: tf may not contain all the words in idf. We need zero padding for words that appear in idf but not in tf!
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



