
AI For Trading: Sentiment Analysis with an RNN (100)
Sentiment Analysis with an RNN
In this notebook, you'll implement a recurrent neural network that performs sentiment analysis.
Using an RNN rather than a strictly feedforward network is more accurate since we can include information about the sequence of words.
Here we'll use a dataset of movie reviews, accompanied by sentiment labels: positive or negative.

Network Architecture
The architecture for this network is shown below.
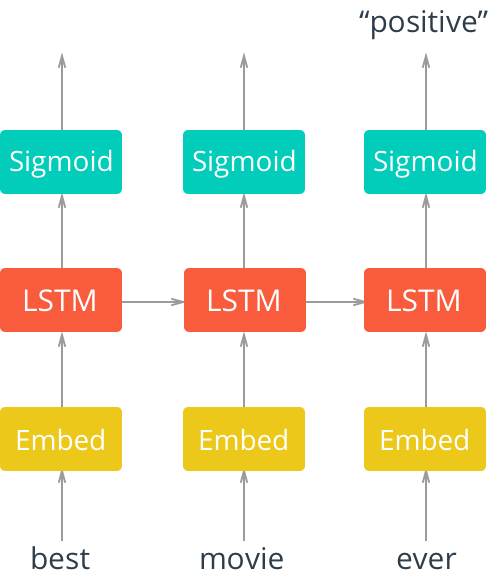
First, we'll pass in words to an embedding layer. We need an embedding layer because we have tens of thousands of words, so we'll need a more efficient representation for our input data than one-hot encoded vectors. You should have seen this before from the Word2Vec lesson. You can actually train an embedding with the Skip-gram Word2Vec model and use those embeddings as input, here. However, it's good enough to just have an embedding layer and let the network learn a different embedding table on its own. In this case, the embedding layer is for dimensionality reduction, rather than for learning semantic representations.
After input words are passed to an embedding layer, the new embeddings will be passed to LSTM cells. The LSTM cells will add recurrent connections to the network and give us the ability to include information about the sequence of words in the movie review data.
Finally, the LSTM outputs will go to a sigmoid output layer. We're using a sigmoid function because positive and negative = 1 and 0, respectively, and a sigmoid will output predicted, sentiment values between 0-1.
We don't care about the sigmoid outputs except for the very last one; we can ignore the rest. We'll calculate the loss by comparing the output at the last time step and the training label (pos or neg).
Load in and visualize the data
import numpy as np
# read data from text files
with open('data/reviews.txt', 'r') as f:
reviews = f.read()
with open('data/labels.txt', 'r') as f:
labels = f.read()print(reviews[:200])
print()
print(labels[:20])bromwell high is a cartoon comedy . it ran at the same time as some other programs about school life such as teachers . my years in the teaching profession lead me to believe that bromwell high
positive
negative
poData pre-processing
The first step when building a neural network model is getting your data into the proper form to feed into the network. Since we're using embedding layers, we'll need to encode each word with an integer. We'll also want to clean it up a bit.
You can see an example of the reviews data above. Here are the processing steps, we'll want to take:
- We'll want to get rid of periods and extraneous punctuation.
- Also, you might notice that the reviews are delimited with newline characters
\n. To deal with those, I'm going to split the text into each review using\nas the delimiter.- Then I can combined all the reviews back together into one big string.
First, let's remove all punctuation. Then get all the text without the newlines and split it into individual words.
from string import punctuation
print(punctuation)
# get rid of punctuation
reviews = reviews.lower() # lowercase, standardize
all_text = ''.join([c for c in reviews if c not in punctuation])!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~# split by new lines and spaces
reviews_split = all_text.split('\n')
all_text = ' '.join(reviews_split)
# create a list of words
words = all_text.split()words[:30]['bromwell',
'high',
'is',
'a',
'cartoon',
'comedy',
'it',
'ran',
'at',
'the',
'same',
'time',
'as',
'some',
'other',
'programs',
'about',
'school',
'life',
'such',
'as',
'teachers',
'my',
'years',
'in',
'the',
'teaching',
'profession',
'lead',
'me']Encoding the words
The embedding lookup requires that we pass in integers to our network. The easiest way to do this is to create dictionaries that map the words in the vocabulary to integers. Then we can convert each of our reviews into integers so they can be passed into the network.
Exercise: Now you're going to encode the words with integers. Build a dictionary that maps words to integers. Later we're going to pad our input vectors with zeros, so make sure the integers start at 1, not 0.
Also, convert the reviews to integers and store the reviews in a new list calledreviews_ints.
# feel free to use this import
from collections import Counter
## Build a dictionary that maps words to integers
# Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value
# @see http://www.pythoner.com/205.html
word_counts = Counter(words)
# print(word_counts)
# Counter({'the': 336713, 'and': 164107})
sorted_vocab = sorted(word_counts, key=word_counts.get, reverse=True)
# print(sorted_vocab)
# vocab_to_int = None
int_to_vocab = {ii: word for ii, word in enumerate(sorted_vocab)}
vocab_to_int = {word: ii for ii, word in int_to_vocab.items()}
## use the dict to tokenize each review in reviews_split
## store the tokenized reviews in reviews_ints
reviews_ints = []
for review in reviews_split:
reviews_ints.append([vocab_to_int[word] for word in review.split()])
Test your code
As a text that you've implemented the dictionary correctly, print out the number of unique words in your vocabulary and the contents of the first, tokenized review.
# stats about vocabulary
print('Unique words: ', len((vocab_to_int))) # should ~ 74000+
print()
# print tokens in first review
print('Tokenized review: \n', reviews_ints[:1])Unique words: 74072
Tokenized review:
[[21024, 307, 5, 2, 1049, 206, 7, 2137, 31, 0, 170, 56, 14, 48, 80, 5784, 43, 381, 109, 139, 14, 5193, 59, 153, 8, 0, 4974, 5851, 474, 70, 4, 259, 11, 21024, 307, 12, 1977, 5, 73, 2394, 4, 612, 72, 5, 5193, 0, 24102, 4, 1982, 10165, 0, 5785, 1498, 35, 50, 65, 203, 144, 66, 1198, 5193, 19868, 0, 37441, 3, 0, 220, 882, 30, 2987, 70, 3, 0, 5786, 9, 685, 1, 66, 1498, 53, 9, 215, 0, 382, 8, 61, 2, 1405, 3685, 782, 4, 3482, 179, 0, 381, 9, 1211, 13582, 31, 307, 2, 348, 340, 2912, 9, 142, 126, 4, 7689, 29, 3, 128, 5193, 1405, 2325, 4, 21024, 307, 9, 527, 11, 108, 1447, 3, 59, 542, 101, 11, 21024, 307, 5, 226, 4145, 47, 2, 2210, 11, 7, 214, 22]]Encoding the labels
Our labels are "positive" or "negative". To use these labels in our network, we need to convert them to 0 and 1.
Exercise: Convert labels from
positiveandnegativeto 1 and 0, respectively, and place those in a new list,encoded_labels.
# 1=positive, 0=negative label conversion
labels_split = labels.split('\n')
encoded_labels = np.array([1 if label == 'positive' else 0 for label in labels_split])
encoded_labels[:20]
array([1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0])Removing Outliers
As an additional pre-processing step, we want to make sure that our reviews are in good shape for standard processing. That is, our network will expect a standard input text size, and so, we'll want to shape our reviews into a specific length. We'll approach this task in two main steps:
- Getting rid of extremely long or short reviews; the outliers
- Padding/truncating the remaining data so that we have reviews of the same length.
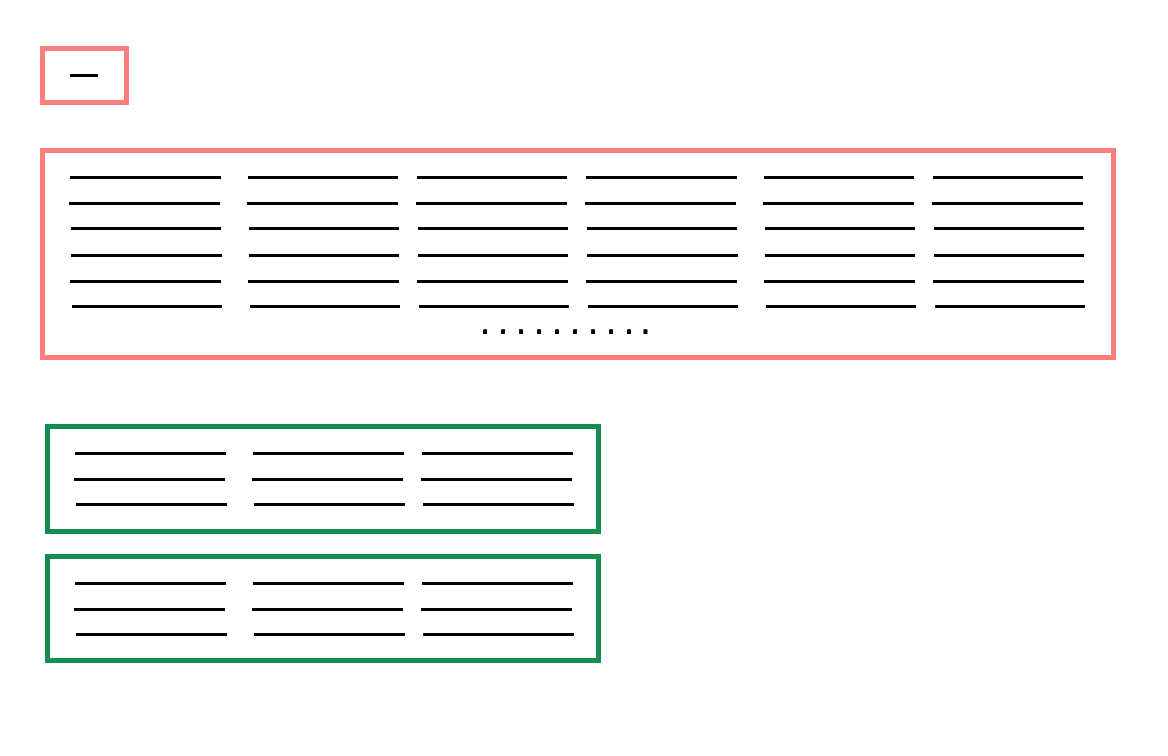
Before we pad our review text, we should check for reviews of extremely short or long lengths; outliers that may mess with our training.
# outlier review stats
review_lens = Counter([len(x) for x in reviews_ints])
print("Zero-length reviews: {}".format(review_lens[0]))
print("Maximum review length: {}".format(max(review_lens)))Zero-length reviews: 1
Maximum review length: 2514Okay, a couple issues here. We seem to have one review with zero length. And, the maximum review length is way too many steps for our RNN. We'll have to remove any super short reviews and truncate super long reviews. This removes outliers and should allow our model to train more efficiently.
Exercise: First, remove any reviews with zero length from the
reviews_intslist and their corresponding label inencoded_labels.
print('Number of reviews before removing outliers: ', len(reviews_ints))
## remove any reviews/labels with zero length from the reviews_ints list.
non_zero_idx = [ii for ii, review in enumerate(reviews_ints) if len(review) != 0]
reviews_ints = [reviews_ints[ii] for ii in non_zero_idx]
encoded_labels = np.array([encoded_labels[ii] for ii in non_zero_idx])
print('Number of reviews after removing outliers: ', len(reviews_ints))Number of reviews before removing outliers: 25001
Number of reviews after removing outliers: 25000Padding sequences
To deal with both short and very long reviews, we'll pad or truncate all our reviews to a specific length. For reviews shorter than some seq_length, we'll pad with 0s. For reviews longer than seq_length, we can truncate them to the first seq_length words. A good seq_length, in this case, is 200.
Exercise: Define a function that returns an array
featuresthat contains the padded data, of a standard size, that we'll pass to the network.
- The data should come from
review_ints, since we want to feed integers to the network.- Each row should be
seq_lengthelements long.- For reviews shorter than
seq_lengthwords, left pad with 0s. That is, if the review is['best', 'movie', 'ever'],[117, 18, 128]as integers, the row will look like[0, 0, 0, ..., 0, 117, 18, 128].- For reviews longer than
seq_length, use only the firstseq_lengthwords as the feature vector.
As a small example, if the seq_length=10 and an input review is:
[117, 18, 128]The resultant, padded sequence should be:
[0, 0, 0, 0, 0, 0, 0, 117, 18, 128]Your final features array should be a 2D array, with as many rows as there are reviews, and as many columns as the specified seq_length.
This isn't trivial and there are a bunch of ways to do this. But, if you're going to be building your own deep learning networks, you're going to have to get used to preparing your data.
def pad_features(reviews_ints, seq_length):
''' Return features of review_ints, where each review is padded with 0's
or truncated to the input seq_length.
'''
## implement function
# getting the correct rows x cols shape
features = np.zeros((len(reviews_ints), seq_length), dtype=int)
print("features\n:", features)
# for each review, I grab that review and
for i, row in enumerate(reviews_ints):
features[i, -len(row):] = np.array(row)[:seq_length]
return features# Test your implementation!
seq_length = 200
features = pad_features(reviews_ints, seq_length=seq_length)
## test statements - do not change - ##
assert len(features)==len(reviews_ints), "Your features should have as many rows as reviews."
assert len(features[0])==seq_length, "Each feature row should contain seq_length values."
# print first 10 values of the first 30 batches
print(features[:30,:10])features
: [[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]
...,
[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]
[0 0 0 ..., 0 0 0]]
[[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[22381 41 46417 14 705 17138 3388 46 76 34]
[ 4504 504 14 2 3341 161 8311 1651 5 4818]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 53 9 13 115 59 797 551 70 363 4]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 329 577 33 2 161 747 2730 8 324]
[ 8 10 10170 5304 1945 688 443 21 279 672]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 306 10398 2068 1564 6201 6527 3287 17945 10627]
[ 0 0 0 0 0 0 0 0 0 0]
[ 20 121 2068 1564 514 8180 87 5 1324 1181]
[ 0 19 5 75 39 5 57 80 94 4]
[ 53 9 83 328 26229 46426 62 9 13 613]
[ 10 19 5 29 1435 32316 3768 689 15099 5]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 39 25 108 17951 1421 8 0 326 3 124]
[ 0 0 0 0 0 0 0 0 0 0]
[ 9 498 0 306 10398 54 73 7 12 29]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0]]Training, Validation, Test
With our data in nice shape, we'll split it into training, validation, and test sets.
Exercise: Create the training, validation, and test sets.
- You'll need to create sets for the features and the labels,
train_xandtrain_y, for example.- Define a split fraction,
split_fracas the fraction of data to keep in the training set. Usually this is set to 0.8 or 0.9.- Whatever data is left will be split in half to create the validation and testing data.
split_frac = 0.8
## split data into training, validation, and test data (features and labels, x and y)
split_idx = int(len(features)*split_frac)
train_x, remaining_x = features[:split_idx], features[split_idx:]
train_y, remaining_y = encoded_labels[:split_idx], encoded_labels[split_idx:]
## print out the shapes of your resultant feature data
test_idx = int(len(remaining_x)*0.5)
val_x, test_x = remaining_x[:test_idx], remaining_x[test_idx:]
val_y, test_y = remaining_y[:test_idx], remaining_y[test_idx:]
print("\t\t\tFeature Shapes:")
print("Train set: \t\t{}".format(train_x.shape),
"\nValidation set: \t{}".format(val_x.shape),
"\nTest set: \t\t{}".format(test_x.shape))
Feature Shapes:
Train set: (20000, 200)
Validation set: (2500, 200)
Test set: (2500, 200)Check your work
With train, validation, and test fractions equal to 0.8, 0.1, 0.1, respectively, the final, feature data shapes should look like:
Feature Shapes:
Train set: (20000, 200)
Validation set: (2500, 200)
Test set: (2500, 200)DataLoaders and Batching
After creating training, test, and validation data, we can create DataLoaders for this data by following two steps:
- Create a known format for accessing our data, using TensorDataset which takes in an input set of data and a target set of data with the same first dimension, and creates a dataset.
- Create DataLoaders and batch our training, validation, and test Tensor datasets.
train_data = TensorDataset(torch.from_numpy(train_x), torch.from_numpy(train_y))
train_loader = DataLoader(train_data, batch_size=batch_size)This is an alternative to creating a generator function for batching our data into full batches.
import torch
from torch.utils.data import TensorDataset, DataLoader
# create Tensor datasets
train_data = TensorDataset(torch.from_numpy(train_x), torch.from_numpy(train_y))
valid_data = TensorDataset(torch.from_numpy(val_x), torch.from_numpy(val_y))
test_data = TensorDataset(torch.from_numpy(test_x), torch.from_numpy(test_y))
# dataloaders
batch_size = 50
# make sure to SHUFFLE your data
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size)
valid_loader = DataLoader(valid_data, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_data, shuffle=True, batch_size=batch_size)# obtain one batch of training data
dataiter = iter(train_loader)
sample_x, sample_y = dataiter.next()
print('Sample input size: ', sample_x.size()) # batch_size, seq_length
print('Sample input: \n', sample_x)
print()
print('Sample label size: ', sample_y.size()) # batch_size
print('Sample label: \n', sample_y)Sample input size: torch.Size([50, 200])
Sample input:
tensor([[ 0, 0, 0, ..., 78, 28, 27267],
[ 0, 0, 0, ..., 10, 17, 209],
[ 59, 514, 47, ..., 23, 10927, 1],
...,
[ 0, 0, 0, ..., 59, 467, 172],
[ 0, 0, 0, ..., 21, 10, 2099],
[ 0, 0, 0, ..., 21, 0, 487]])
Sample label size: torch.Size([50])
Sample label:
tensor([ 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1,
1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1,
1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 1,
0, 1, 1, 1, 1, 1, 0, 0])Sentiment Network with PyTorch
Below is where you'll define the network.
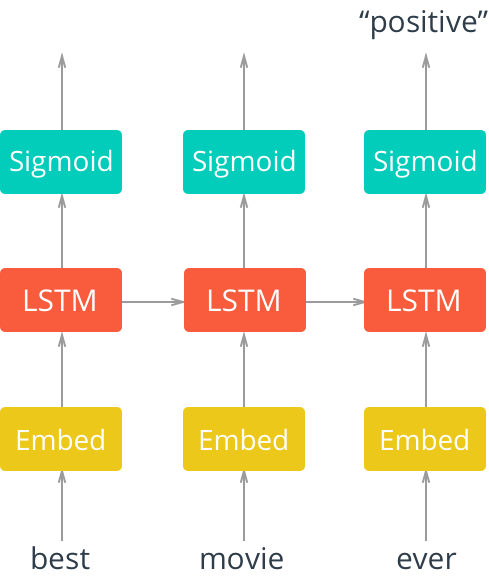
The layers are as follows:
- An embedding layer that converts our word tokens (integers) into embeddings of a specific size.
- An LSTM layer defined by a hidden_state size and number of layers
- A fully-connected output layer that maps the LSTM layer outputs to a desired output_size
- A sigmoid activation layer which turns all outputs into a value 0-1; return only the last sigmoid output as the output of this network.
The Embedding Layer
We need to add an embedding layer because there are 74000+ words in our vocabulary. It is massively inefficient to one-hot encode that many classes. So, instead of one-hot encoding, we can have an embedding layer and use that layer as a lookup table. You could train an embedding layer using Word2Vec, then load it here. But, it's fine to just make a new layer, using it for only dimensionality reduction, and let the network learn the weights.
The LSTM Layer(s)
We'll create an LSTM to use in our recurrent network, which takes in an input_size, a hidden_dim, a number of layers, a dropout probability (for dropout between multiple layers), and a batch_first parameter.
Most of the time, you're network will have better performance with more layers; between 2-3. Adding more layers allows the network to learn really complex relationships.
Exercise: Complete the
__init__,forward, andinit_hiddenfunctions for the SentimentRNN model class.
Note: init_hidden should initialize the hidden and cell state of an lstm layer to all zeros, and move those state to GPU, if available.
# First checking if GPU is available
train_on_gpu=torch.cuda.is_available()
if(train_on_gpu):
print('Training on GPU.')
else:
print('No GPU available, training on CPU.')Training on GPU.import torch.nn as nn
class SentimentRNN(nn.Module):
"""
The RNN model that will be used to perform Sentiment analysis.
"""
def __init__(self, vocab_size, output_size, embedding_dim, hidden_dim, n_layers, drop_prob=0.5):
"""
Initialize the model by setting up the layers.
"""
super(SentimentRNN, self).__init__()
self.output_size = output_size
self.n_layers = n_layers
self.hidden_dim = hidden_dim
# define all layers
# embedding and LSTM layers
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, n_layers,
dropout=drop_prob, batch_first=True)
# dropout layer
self.dropout = nn.Dropout(0.3)
# linear and sigmoid layers
self.fc = nn.Linear(hidden_dim, output_size)
self.sig = nn.Sigmoid()
def forward(self, x, hidden):
"""
Perform a forward pass of our model on some input and hidden state.
"""
batch_size = x.size(0)
# embeddings and lstm_out
x = x.long()
embeds = self.embedding(x)
lstm_out, hidden = self.lstm(embeds, hidden)
# stack up lstm outputs
lstm_out = lstm_out.contiguous().view(-1, self.hidden_dim)
# dropout and fully-connected layer
out = self.dropout(lstm_out)
out = self.fc(out)
# sigmoid function
sig_out = self.sig(out)
# reshape to be batch_size first
sig_out = sig_out.view(batch_size, -1)
sig_out = sig_out[:, -1] # get last batch of labels
# return last sigmoid output and hidden state
return sig_out, hidden
def init_hidden(self, batch_size):
''' Initializes hidden state '''
# Create two new tensors with sizes n_layers x batch_size x hidden_dim,
# initialized to zero, for hidden state and cell state of LSTM
weight = next(self.parameters()).data
if (train_on_gpu):
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().cuda(),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().cuda())
else:
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_(),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_())
return hidden
Instantiate the network
Here, we'll instantiate the network. First up, defining the hyperparameters.
vocab_size: Size of our vocabulary or the range of values for our input, word tokens.output_size: Size of our desired output; the number of class scores we want to output (pos/neg).embedding_dim: Number of columns in the embedding lookup table; size of our embeddings.hidden_dim: Number of units in the hidden layers of our LSTM cells. Usually larger is better performance wise. Common values are 128, 256, 512, etc.n_layers: Number of LSTM layers in the network. Typically between 1-3
Exercise: Define the model hyperparameters.
# Instantiate the model w/ hyperparams
vocab_size = len(vocab_to_int)+1 # +1 for the 0 padding + our word tokens
output_size = 1
embedding_dim = 400
hidden_dim = 256
n_layers = 2
net = SentimentRNN(vocab_size, output_size, embedding_dim, hidden_dim, n_layers)
print(net)SentimentRNN(
(embedding): Embedding(74073, 400)
(lstm): LSTM(400, 256, num_layers=2, batch_first=True, dropout=0.5)
(dropout): Dropout(p=0.3)
(fc): Linear(in_features=256, out_features=1, bias=True)
(sig): Sigmoid()
)Training
Below is the typical training code. If you want to do this yourself, feel free to delete all this code and implement it yourself. You can also add code to save a model by name.
We'll also be using a new kind of cross entropy loss, which is designed to work with a single Sigmoid output. BCELoss, or Binary Cross Entropy Loss, applies cross entropy loss to a single value between 0 and 1.
We also have some data and training hyparameters:
lr: Learning rate for our optimizer.epochs: Number of times to iterate through the training dataset.clip: The maximum gradient value to clip at (to prevent exploding gradients).
# loss and optimization functions
lr=0.001
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# training params
epochs = 4 # 3-4 is approx where I noticed the validation loss stop decreasing
counter = 0
print_every = 100
clip=5 # gradient clipping
# move model to GPU, if available
if(train_on_gpu):
net.cuda()
net.train()
# train for some number of epochs
for e in range(epochs):
# initialize hidden state
h = net.init_hidden(batch_size)
# batch loop
for inputs, labels in train_loader:
counter += 1
if(train_on_gpu):
inputs, labels = inputs.cuda(), labels.cuda()
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
h = tuple([each.data for each in h])
# zero accumulated gradients
net.zero_grad()
# get the output from the model
output, h = net(inputs, h)
# calculate the loss and perform backprop
loss = criterion(output.squeeze(), labels.float())
loss.backward()
# `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.
nn.utils.clip_grad_norm_(net.parameters(), clip)
optimizer.step()
# loss stats
if counter % print_every == 0:
# Get validation loss
val_h = net.init_hidden(batch_size)
val_losses = []
net.eval()
for inputs, labels in valid_loader:
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
val_h = tuple([each.data for each in val_h])
if(train_on_gpu):
inputs, labels = inputs.cuda(), labels.cuda()
output, val_h = net(inputs, val_h)
val_loss = criterion(output.squeeze(), labels.float())
val_losses.append(val_loss.item())
net.train()
print("Epoch: {}/{}...".format(e+1, epochs),
"Step: {}...".format(counter),
"Loss: {:.6f}...".format(loss.item()),
"Val Loss: {:.6f}".format(np.mean(val_losses)))Epoch: 1/4... Step: 100... Loss: 0.676203... Val Loss: 0.651595
Epoch: 1/4... Step: 200... Loss: 0.784058... Val Loss: 1.038054
Epoch: 1/4... Step: 300... Loss: 0.698657... Val Loss: 0.691721
Epoch: 1/4... Step: 400... Loss: 0.669044... Val Loss: 0.669078
Epoch: 2/4... Step: 500... Loss: 0.552629... Val Loss: 0.604350
Epoch: 2/4... Step: 600... Loss: 0.344475... Val Loss: 0.581824
Epoch: 2/4... Step: 700... Loss: 0.428507... Val Loss: 0.475188
Epoch: 2/4... Step: 800... Loss: 0.357084... Val Loss: 0.439305
Epoch: 3/4... Step: 900... Loss: 0.385310... Val Loss: 0.446911
Epoch: 3/4... Step: 1000... Loss: 0.318923... Val Loss: 0.433838
Epoch: 3/4... Step: 1100... Loss: 0.258087... Val Loss: 0.425925
Epoch: 3/4... Step: 1200... Loss: 0.330951... Val Loss: 0.553698
Epoch: 4/4... Step: 1300... Loss: 0.176940... Val Loss: 0.446993
Epoch: 4/4... Step: 1400... Loss: 0.159311... Val Loss: 0.460857
Epoch: 4/4... Step: 1500... Loss: 0.152515... Val Loss: 0.487307
Epoch: 4/4... Step: 1600... Loss: 0.223241... Val Loss: 0.474548Testing
There are a few ways to test your network.
-
Test data performance: First, we'll see how our trained model performs on all of our defined test_data, above. We'll calculate the average loss and accuracy over the test data.
-
Inference on user-generated data: Second, we'll see if we can input just one example review at a time (without a label), and see what the trained model predicts. Looking at new, user input data like this, and predicting an output label, is called inference.
# Get test data loss and accuracy
test_losses = [] # track loss
num_correct = 0
# init hidden state
h = net.init_hidden(batch_size)
net.eval()
# iterate over test data
for inputs, labels in test_loader:
# Creating new variables for the hidden state, otherwise
# we'd backprop through the entire training history
h = tuple([each.data for each in h])
if(train_on_gpu):
inputs, labels = inputs.cuda(), labels.cuda()
# get predicted outputs
output, h = net(inputs, h)
# calculate loss
test_loss = criterion(output.squeeze(), labels.float())
test_losses.append(test_loss.item())
# convert output probabilities to predicted class (0 or 1)
pred = torch.round(output.squeeze()) # rounds to the nearest integer
# compare predictions to true label
correct_tensor = pred.eq(labels.float().view_as(pred))
correct = np.squeeze(correct_tensor.numpy()) if not train_on_gpu else np.squeeze(correct_tensor.cpu().numpy())
num_correct += np.sum(correct)
# -- stats! -- ##
# avg test loss
print("Test loss: {:.3f}".format(np.mean(test_losses)))
# accuracy over all test data
test_acc = num_correct/len(test_loader.dataset)
print("Test accuracy: {:.3f}".format(test_acc))Test loss: 0.480
Test accuracy: 0.819Inference on a test review
You can change this test_review to any text that you want. Read it and think: is it pos or neg? Then see if your model predicts correctly!
Exercise: Write a
predictfunction that takes in a trained net, a plain text_review, and a sequence length, and prints out a custom statement for a positive or negative review!
- You can use any functions that you've already defined or define any helper functions you want to complete
predict, but it should just take in a trained net, a text review, and a sequence length.
# negative test review
test_review_neg = 'The worst movie I have seen; acting was terrible and I want my money back. This movie had bad acting and the dialogue was slow.'
from string import punctuation
def tokenize_review(test_review):
test_review = test_review.lower() # lowercase
# get rid of punctuation
test_text = ''.join([c for c in test_review if c not in punctuation])
# splitting by spaces
test_words = test_text.split()
# tokens
test_ints = []
test_ints.append([vocab_to_int[word] for word in test_words])
return test_ints
# test code and generate tokenized review
test_ints = tokenize_review(test_review_neg)
print(test_ints)[[0, 246, 17, 9, 27, 107, 112, 13, 387, 1, 9, 180, 59, 272, 143, 10, 17, 67, 75, 112, 1, 0, 409, 13, 538]]# test sequence padding
seq_length=200
features = pad_features(test_ints, seq_length)
print(features)features
: [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 246 17 9 27
107 112 13 387 1 9 180 59 272 143 10 17 67 75 112 1 0 409
13 538]]# test conversion to tensor and pass into your model
feature_tensor = torch.from_numpy(features)
print(feature_tensor.size())torch.Size([1, 200])def predict(net, test_review, sequence_length=200):
''' Prints out whether a give review is predicted to be
positive or negative in sentiment, using a trained model.
params:
net - A trained net
test_review - a review made of normal text and punctuation
sequence_length - the padded length of a review
'''
# print custom response based on whether test_review is pos/neg
net.eval()
# tokenize review
test_ints = tokenize_review(test_review)
# pad tokenized sequence
seq_length=sequence_length
features = pad_features(test_ints, seq_length)
# convert to tensor to pass into your model
feature_tensor = torch.from_numpy(features)
batch_size = feature_tensor.size(0)
# initialize hidden state
h = net.init_hidden(batch_size)
if(train_on_gpu):
feature_tensor = feature_tensor.cuda()
# get the output from the model
output, h = net(feature_tensor, h)
# convert output probabilities to predicted class (0 or 1)
pred = torch.round(output.squeeze())
# printing output value, before rounding
print('Prediction value, pre-rounding: {:.6f}'.format(output.item()))
# print custom response
if(pred.item()==1):
print("Positive review detected!")
else:
print("Negative review detected.")
# positive test review
test_review_pos = 'This movie had the best acting and the dialogue was so good. I loved it.'
# call function
# try negative and positive reviews!
seq_length=200
predict(net, test_review_neg, seq_length)features
: [[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
Prediction value, pre-rounding: 0.003688
Negative review detected.Try out test_reviews of your own!
Now that you have a trained model and a predict function, you can pass in any kind of text and this model will predict whether the text has a positive or negative sentiment. Push this model to its limits and try to find what words it associates with positive or negative.
Later, you'll learn how to deploy a model like this to a production environment so that it can respond to any kind of user data put into a web app!
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


