
Python 基础六-脚本编写
今天开始学习Python的脚本。
Python3 安装和环境设置
1、Anaconda集成包环境安装
要利用Python进行科学计算,就需要一一安装所需的模块,而这些模块可能又依赖于其它的软件包或库,因而安装和使用起来相对麻烦。幸好有人专门在做这一类事情,将科学计算所需要的模块都编译好,然后打包以发行版的形式供用户使用,Anaconda就是其中一个常用的科学计算发行版。
Anaconda 是一个包含数据科学常用包的 Python 发行版本。它基于 conda ——一个包和环境管理器——衍生而来。你将使用 conda 创建环境,以便分隔使用不同 Python 版本和不同程序包的项目。你还将使用它在环境中安装、卸载和更新包。通过使用 Anaconda,处理数据的过程将更加愉快。
Jupyter notebook 是一种 Web 文档,能让你将文本、图像和代码全部组合到一个文档中。它事实上已经成为数据分析的标准环境。Jupyter notebook 源自 2011 年的 IPython 项目,之后迅速流行起来。在本课程的第二节课中,你将使用 Jupyter notebook 进行分析工作。
安装
Anaconda 可用于 Windows、Mac OS X 和 Linux。可以在 https://www.anaconda.com/download/ 上找到安装程序和安装说明。
在Mac环境下:
添加环境变量:
编辑.bash_profile
sudo vim ~/.bash_profile在.bash_profile文件中添加下面文本
export PATH="/Users/dangyuan/anaconda3/bin:$PATH"刷新生效source
source ~/.bash_profile输入python即可进入anaconda
➜ ~ python
Python 3.7.0 (default, Jun 28 2018, 07:39:16)
[Clang 4.0.1 (tags/RELEASE_401/final)] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>卸载Anaconda
命令行输入:
m -rf ~/anaconda3
vim ~/.bash_profile
#删去anaconda 的路径
rm -rf ~/.condarc ~/.conda ~/.continuum手动去删除文件夹:
手动删除文件夹,然后再去把配置文件里面对应的环境变量删了。
管理包
包管理器用于在计算机上安装库和其他软件。你可能已经熟悉 pip,它是 Python 库的默认包管理器。conda 与 pip 相似,不同之处是可用的包以数据科学包为主,而 pip 适合一般用途。与此同时,conda 并非像 pip 那样专门适用于 Python,它也可以安装非 Python 的包。它是支持任何软件的包管理器。也就是说,虽然并非所有的 Python 库都能通过 Anaconda 发行版和 conda 获得,但同时它也支持非 Python 库的获得。在使用 conda 的同时,你仍可以使用 pip 来安装包
安装了 Anaconda 之后,管理包是相当简单的。要安装包,请在终端中键入conda install package_name。例如,要安装 numpy,请键入conda install numpy。
你还可以同时安装多个包。类似 conda install numpy scipy pandas 的命令会同时安装所有这些包。还可以通过添加版本号(例如 conda install numpy=1.10)来指定所需的包版本。
Conda 还会自动为你安装依赖项。例如,scipy 依赖于 numpy,因为它使用并需要 numpy。如果你只安装 scipy (conda install scipy),则 conda 还会安装 numpy(如果尚未安装的话)。
大多数命令都是很直观的。要卸载包,请使用 conda remove package_name。要更新包,请使用 conda update package_name。如果想更新环境中的所有包(这样做常常很有用),请使用 conda update --all。最后,要列出已安装的包,请使用前面提过的 conda list。
如果不知道要找的包的确切名称,可以尝试使用 conda search search_term 进行搜索。例如,我知道我想安装 Beautiful Soup,但我不清楚确切的包名称。因此,我尝试执行 conda search beautifulsoup。
最佳做法
使用环境
对我有很大帮助的一点是,我的 Python 2 和 Python 3 具有独立的环境。我使用了 conda create -n py2 python=2 和 conda create -n py3 python=3 创建两个独立的环境,即 py2 和 py3。现在,我的每个 Python 版本都有一个通用环境。在所有这些环境中,我都安装了大多数常用的标准数据科学包(numpy、scipy、pandas 等)。
我还发现,为我从事的每个项目创建环境很有用。这对于与数据不相关的项目(例如使用 Flask 开发的 Web 应用)也很有用。例如,我为我的个人博客(使用 Pelican)创建了一个环境。
2、Atom编辑器
使用 Atom编辑器,设置Tab为四个空格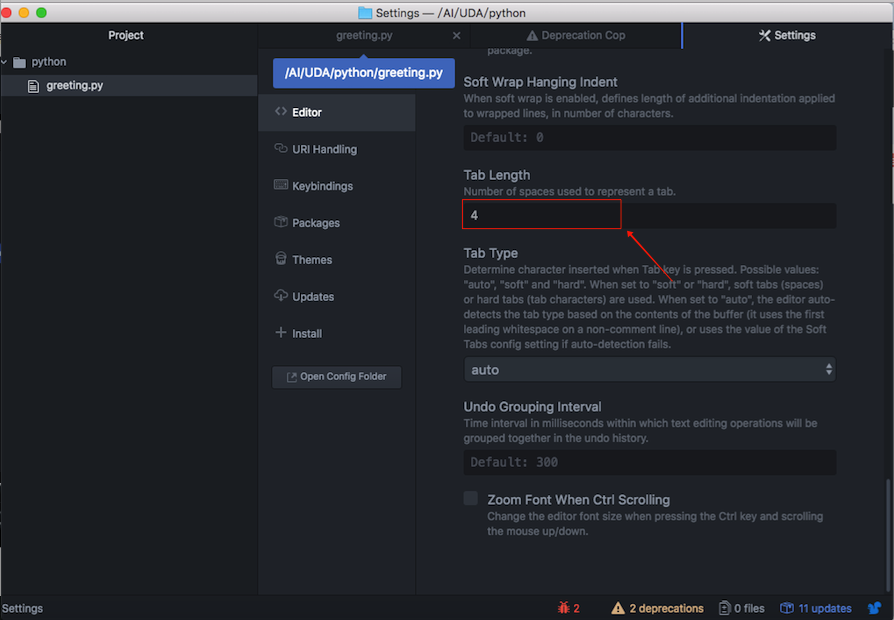
pylint 插件使用
与用户输入交互
我们可以使用内置函数 input 获取用户的原始输入,该函数接受一个可选字符串参数,用于指定在要求用户输入时向用户显示的消息。
name = input("Enter your name: ")
print("Hello there, {}!".format(name.title()))这段代码提示用户输入姓名,然后在问候语中使用该输入。input 函数获取用户输入的任何内容并将其存储为字符串。如果你想将输入解析为字符串之外的其他类型,例如整数(如以下示例所示),需要用新的类型封装结果并从字符串转换为该类型。
num = int(input("Enter an integer"))
print("hello" * num)我们还可以使用内置函数 eval 将用户输入解析为 Python 表达式。该函数会将字符串评估为一行 Python 代码。
result = eval(input("Enter an expression: "))
print(result)如果用户输入 2 * 3,输出为 6。
练习:
假设你是一名老师,需要向每位学生发一条消息,提醒他们未交的作业和分数是多少。你知道每名学生的姓名,没交的作业份数和分数,这些数据保存在了电子表格中,你只需将这些输入插入你想到的以下消息中即可:
Hi [insert student name],
This is a reminder that you have [insert number of missing assignments] assignments left to submit before you can graduate. Your current grade is [insert current grade] and can increase to [insert potential grade] if you submit all assignments before the due date.你可以将此消息复制粘贴后发送给每位学生,并且每次手动插入相应的值。但是你要写一个程序来帮助你完成这一流程。
写一个完成以下操作的脚本:
- 1.请求用户输入三次。一次是名字列表,一次是未交作业数量列表,一次是分数列表。使用该输入创建 names、assignments 和 grades 列表。
- 2.使用循环为每个学生输出一条信息并包含正确的值。潜在分数是 2 乘以未交作业数加上当前分数。
下面是在终端内成功运行该脚本的示例。
第一种方法:
# -*- coding:utf-8 -*-
"""
写一个完成以下操作的脚本:
1. 请求用户输入三次。一次是名字列表,一次是未交作业数量列表,一次是分数列表。使用该输入创建 names、assignments 和 grades 列表。
2. 使用循环为每个学生输出一条信息并包含正确的值。潜在分数是 2 乘以未交作业数加上当前分数。
"""
names = input("Enter names separated by commas: ").title().split(",")
assignments = input("Enter assignment counts separated by commas: ").split(",")
grades = input("Enter grades separated by commas: ").split(",")
mess_str = """
Hi {},
This is a reminder that you have {} assignments left to submit before you can graduate. Your current grade is {} and can increase to {} if you submit all assignments before the due date.
"""
for i in range(4):
name = names[i]
assign = assignments[i]
grade = grades[i]
next_grade = assgin * 2 + grade
print(mess_str.format(name,assgin,grade,next_grade))
第二种综合方法:
names = input("Enter names separated by commas: ").title().split(",")
assignments = input("Enter assignment counts separated by commas: ").split(",")
grades = input("Enter grades separated by commas: ").split(",")
message = "Hi {},\n\nThis is a reminder that you have {} assignments left to \
submit before you can graduate. You're current grade is {} and can increase \
to {} if you submit all assignments before the due date.\n\n"
for name, assignment, grade in zip(names, assignments, grades):
print(message.format(name, assignment, grade, int(grade) + int(assignment)*2))
处理异常
错误和异常
-
当 Python 无法解析代码时,就会发生语法错误,因为我们没有遵守正确的 Python 语法。当你出现拼写错误或第一次开始学习 Python 时,可能会遇到这些错误。
-
当在程序执行期间出现意外情况时,就会发生异常,即使代码在语法上正确无误。Python 有不同类型的内置异常,你可以在错误消息中查看系统抛出了什么异常。
指定异常
我们实际上可以指定要在 except 块中处理哪个错误,如下所示:
try:
# some code
except ValueError:
# some code现在它会捕获 ValueError 异常,但是不会捕获其他异常。如果我们希望该处理程序处理多种异常,我们可以在 except 后面添加异常元组。
try:
# some code
except (ValueError, KeyboardInterrupt):
# some code或者,如果我们希望根据异常执行不同的代码块,可以添加多个 except 块。
try:
# some code
except ValueError:
# some code
except KeyboardInterrupt:
# some code练习解决方案:处理除以零的情形
def create_groups(items, num_groups):
try:
size = len(items) // num_groups
except ZeroDivisionError:
print("WARNING: Returning empty list. Please use a nonzero number.")
return []
else:
groups = []
for i in range(0, len(items), size):
groups.append(items[i:i + size])
return groups
finally:
print("{} groups returned.".format(num_groups))
print("Creating 6 groups...")
for group in create_groups(range(32), 6):
print(list(group))
print("\nCreating 0 groups...")
for group in create_groups(range(32), 0):
print(list(group))访问错误消息
在处理异常时,依然可以如下所示地访问其错误消息:
try:
# some code
except ZeroDivisionError as e:
# some code
print("ZeroDivisionError occurred: {}".format(e))应该会输出如下所示的结果:
ZeroDivisionError occurred: division by zero因此依然可以访问错误消息,即使已经处理异常以防止程序崩溃!
如果没有要处理的具体错误,依然可以如下所示地访问消息:
try:
# some code
except Exception as e:
# some code
print("Exception occurred: {}".format(e))Exception 是所有内置异常的基础类。你可以在此处详细了解 Python 的异常。
读写文件
读取文件
f = open('my_path/my_file.txt', 'r')
file_data = f.read()
f.close()- 1、首先使用内置函数 open 打开文件。需要文件路径字符串。open 函数会返回文件对象,它是一个 Python 对象,Python 通过该对象与文件本身交互。在此示例中,我们将此对象赋值给变量 f。
- 2、你可以在
open函数中指定可选参数。参数之一是打开文件时采用的模式。在此示例中,我们使用 r,即只读模式。这实际上是模式参数的默认值。 - 3、使用
read访问文件对象的内容。该 read 方法会接受文件中包含的文本并放入字符串中。在此示例中,我们将该方法返回的字符串赋值给变量 file_data。 - 4、当我们处理完文件后,使用
close方法释放该文件占用的系统资源。
写入文件
f = open('my_path/my_file.txt', 'w')
f.write("Hello there!")
f.close()- 1、以写入 ('w') 模式打开文件。如果文件不存在,Python 将为你创建一个文件。如果以写入模式打开现有文件,该文件中之前包含的所有内容将被删除。如果你打算向现有文件添加内容,但是不删除其中的内容,可以使用附加 ('a') 模式,而不是写入模式。
- 2、使用 write 方法向文件中添加文本。
- 3、操作完毕后,关闭文件。
With
Python 提供了一个特殊的语法,该语法会在你使用完文件后自动关闭该文件。
with open('my_path/my_file.txt', 'r') as f:
file_data = f.read()该 with 关键字使你能够打开文件,对文件执行操作,并在缩进代码(在此示例中是读取文件)执行之后自动关闭文件。现在,我们不需要调用 f.close() 了!你只能在此缩进块中访问文件对象 f。
readline()
找到读取文件下一行的方法
循环读取文件内容
很方便的是,Python 将使用语法for line in file 循环访问文件中的各行内容。 我可以使用该语法创建列表中的行列表。因为每行依然包含换行符,因此我使用.strip() 删掉换行符。
camelot_lines = []
with open("camelot.txt") as f:
for line in f:
camelot_lines.append(line.strip())
print(camelot_lines)练习:《飞翔的马戏团》 演员名单
你将创建一个演员名单,列出参演电视剧《巨蟒剧团之飞翔的马戏团》的演员。
写一个叫做 create_cast_list 的函数,该函数会接受文件名作为输入,并返回演员姓名列表。 它将运行文件 flying_circus_cast.txt(信息收集自 imdb.com)。文件的每行包含演员姓名、逗号,以及关于节目角色的一些(凌乱)信息。你只需提取姓名,并添加到列表中。你可以使用 .split() 方法处理每行。
代码:
def create_cast_list(filename):
cast_list = []
#use with to open the file filename
with open(filename) as f:
for line in f:
item = line.split(",")
cast_list.append(item[0])
#use the for loop syntax to process each line
#and add the actor name to cast_list
return cast_list
cast_list = create_cast_list('flying_circus_cast.txt')
for actor in cast_list:
print(actor)导入本地、标准和第三方模块
导入本地脚本
我们实际上可以导入其他脚本中的 Python,如果你处理的是大型项目,需要将代码整理成多个文件并重复利用这些文件中的代码,则导入脚本很有用。如果你要导入的 Python 脚本与当前脚本位于同一个目录下,只需输入 import,然后是文件名,无需扩展名 .py。
import useful_functionsImport语句写在 Python 脚本的顶部,每个导入语句各占一行。该 import 语句会创建一个模块对象,叫做 useful_functions。模块是包含定义和语句的 Python 文件。要访问导入模块中的对象,需要使用点记法。
import useful_functions
useful_functions.add_five([1, 2, 3, 4])我们可以为导入模块添加别名,以使用不同的名称引用它。
import useful_functions as uf
uf.add_five([1, 2, 3, 4])使用 if main 块
为了避免运行从其他脚本中作为模块导入的脚本中的可执行语句,将这些行包含在if __name__ == "__main__"块中。或者,将它们包含在函数 main() 中并在if main 块中调用该函数。
每当我们运行此类脚本时,Python 实际上会为所有模块设置一个特殊的内置变量 name。当我们运行脚本时,Python 会将此模块识别为主程序,并将此模块的 name 变量设为字符串 "main"。对于该脚本中导入的任何模块,这个内置 name 变量会设为该模块的名称。因此,条件 if name == "main"会检查该模块是否为主程序。
小试牛刀:
请在同一目录下创建这些脚本,并在终端里运行这些脚本!实验if main 块并访问导入模块中的对象!
# demo.py
import useful_functions as uf
scores = [88, 92, 79, 93, 85]
mean = uf.mean(scores)
curved = uf.add_five(scores)
mean_c = uf.mean(curved)
print("Scores:", scores)
print("Original Mean:", mean, " New Mean:", mean_c)
print(__name__)
print(uf.__name__)# useful_functions.py
def mean(num_list):
return sum(num_list) / len(num_list)
def add_five(num_list):
return [n + 5 for n in num_list]
def main():
print("Testing mean function")
n_list = [34, 44, 23, 46, 12, 24]
correct_mean = 30.5
assert(mean(n_list) == correct_mean)
print("Testing add_five function")
correct_list = [39, 49, 28, 51, 17, 29]
assert(add_five(n_list) == correct_list)
print("All tests passed!")
if __name__ == '__main__':
main()在解释器中进行实验
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



