
谷粒商城-高级-36 全文检索 Elasticsearch-入门基础用法
一、增删改查
创建索引
一般创建索引,我们要指定分片和复制的数量,以及指定对字段进行mapping设置,mapping设置很重要,会影响后期的查询效率。
PUT test_create_index
{
"settings": {
"number_of_shards": 3, // 分片
"number_of_replicas": 1 // 复制
},
"mappings": {
"test_type":{ // 指定类型
"properties":{ // 定义字段的mapping
"name": {
"type": "keyword"
},
"time": {
"type": "date",
"format": "epoch_millis"
}
}
}
}
}增加字段,并配置mapping
// 已配置mapping的字段,一般不可修改
PUT test_create_index/_mapping/test_type
{
"properties": {
"padd":{
"type":"keyword"
}
}
}删除索引
DELETE website插入文档
// 指定文档的id,如果索引不存在,会自动重新建索引,在插入
PUT test_create_index/test_type/1
{
"name": "lodge",
"time": "20190627142300"
}
// 由es自动生成id,如果索引不存在,会自动重新建索引,在插入
POST test_create_index/test_type
{
"name": "lodge1",
"time": "20190627122300"
}批量插入
插入多条数据,目前只能用 _bulk API来实现,index表示新插入数据,create同理,在python的index()方法中op_type=create表示如果index不存在那么直接创建index并插入数据,而op_type=index表示向已存在的index中插数据,此外还可以一起bulk delete、update等操作。
PUT test/books/_bulk
{ "index":{"_id":4}}
{"name":"《围城》","price":101}
{ "index":{"_id":5}}
{"name":"《格林童话》","price":108}
}
#如果你不想设置主键_id,那么可以直接置空,系统会创建默认主键,写法如下:
PUT test/books/_bulk
{ "index":{}}
{"name":"《围城》","price":101}
{ "index":{}}
{"name":"《格林童话》","price":108}注意插入数据时如果指定的_id已经存在,那么新插入的数据会直接替换原ID的数据。
更新文档
// 更新操作原理,先查询这个文档,进行修改,删除旧文档,插入新的文档
// 如果原来没有文档存在,那么这操作为插入操作。如果原来有文档存在,那么这操作为替换覆盖
PUT test_create_index/test_type/1
{
"name": "lodge2",
"time": "20190727122300"
}
// 这个更新操作,加上_create,是不覆盖原有的文档,会抛异常409
PUT test_create_index/test_type/1/_create
{
"name": "lodge2",
"time": "20190727122300"
}
// 这个更新操作,加上_update,是在原有的文档上进行修改,增加字段和值
POST test_create_index/test_type/1/_update
{
"doc": {
"passed": "20190631"
}
}
// 这个更新操作,加上_update,是在原有的文档上进行修改,替换字段的某个值
POST test_create_index/test_type/1/_update
{
"script" : "ctx._source.passed='swdhkf'"
}
// 更新操作,在高并发时候,经常会遇到冲突,数据幻读的问题
// 可以采取乐观锁并发控制,使用es自带的版本号控制。更新时候发现版本号不对,会抛异常409
PUT test_create_index/test_type/1/_update?version=2
{
"name": "lodge2",
"time": "20190727122300"
}
删除文档
// 删除指定id的文档
DELETE test_create_index/test_type/1查询
// 查询索引,这操作只能使用curl
curl IP地址:端口号/_cat/indices?v
#查询当前所有的index,这里调用了_cat的API
GET _cat/indices
// 查询指定索引的信息(settings,mappings)
GET test_create_index
// 查询索引下指定类型的mapping配置
GET test_create_index/test_type/_mapping
// 查询文档数据量
GET test_create_index/test_type/_count
// 查询指定id文档,只显示文档数据
GET test_create_index/test_type/1/_source
// 查询一条指定id文档
GET test_create_index/test_type/1
// 查询多条指定id文档
POST test_create_index/_mget
{
"ids" : [ "AWuXm5qe5IAaRF19nMIv", "1" ]
}
// 查询所有文档
GET test_create_index/_search二、进阶检索
1、导入批量数据
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
}官方准备的示例:https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json
在Kibana中导入批量数据: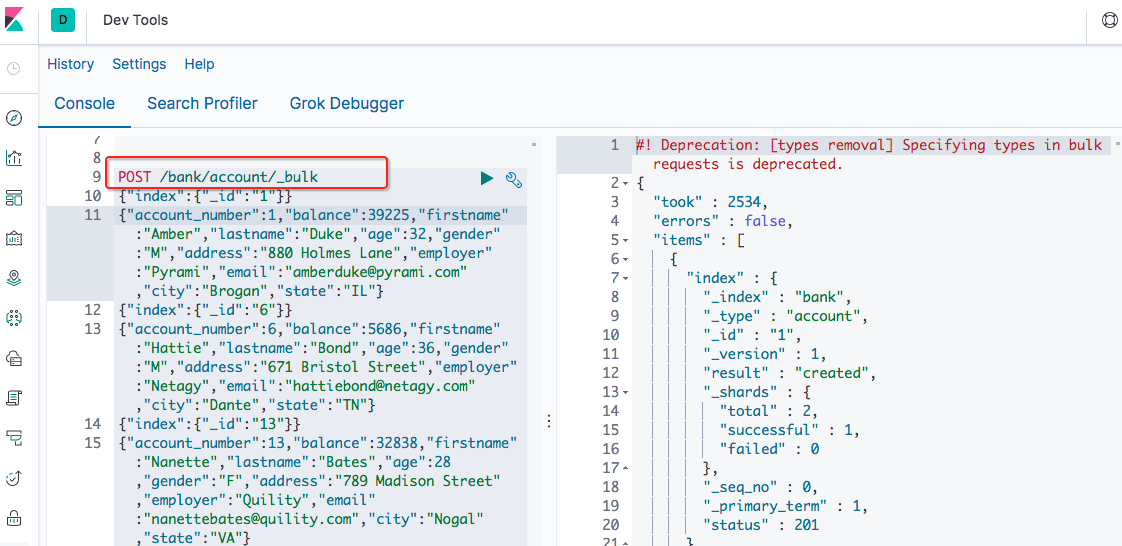
POST /bank/account/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
...2、SearchAPI
ES 支持两种基本方式检索:
- 一个是通过使用 REST request URI 发送搜索参数(uri+检索参数)
- 另一个是通过使用 REST request body 来发送它们(uri+请求体)
3、返回结构
{
"took": 20, // 整个搜索请求花费的毫秒数
"timed_out": false, // 查询超时与否,false没有超时, true为超时
"_shards": {
"total": 5, // 分片数量
"successful": 5, // 成功的分片数量,即是没有故障的分片
"failed": 0 // 失败的分片数量,即是出现故障的分片
},
"hits": {
"total": 100000, // 查询整个索引的文档数量
"max_score": 1, // 所有文档匹配查询中_score的最大值
"hits": [
{
"_index": "test_index", // 索引名称
"_type": "test_index", // 索引类型
"_id": "030180142347", // 文档id
"_score": 1, // 这条文档与查询的条件匹配程度
"_source": { // 文档的json数据
"name": "lodge",
"age": 25
}
}
]
}
}4、查询方式
1、GET查询方式
// 在所有索引的所有类型中搜索
GET /_search
// 在索引test_index的所有类型中搜索
GET /test_index/_search
// 在索引test_index和test_index1的所有类型中搜索
// 多个索引查询
GET /test_index,test_index1/_search
// 在索引以test开头的所有类型中搜索
// 正则查询
GET /test_*/_search
// 在所有索引的user和tweet的类型中搜索
GET /_all/user,tweet/_search
// 条件查询文档
GET /test_index/_search?q=字段名:对应的值
// 分页查询,size代表结果数量,from代表跳过开始的结果数
// size相当sql的limit,from相当sql的offset
GET /test_index/_search?size=5&from=10示例:
GET bank/_search?q=*&sort=account_number:desc2、POST 查询方式(请求体查询方式)
// 请求体基本结构
{
"query": {}, // 相当sql的where条件
"sort": {}, // 相当sql的order by排序
"from":0, // 相当sql的offset从第几行获取
"size":20, // 相当sql的limit返回数据量
"_source": [] // 获取那些文档字段数据
}query内部简单包含关系的示意图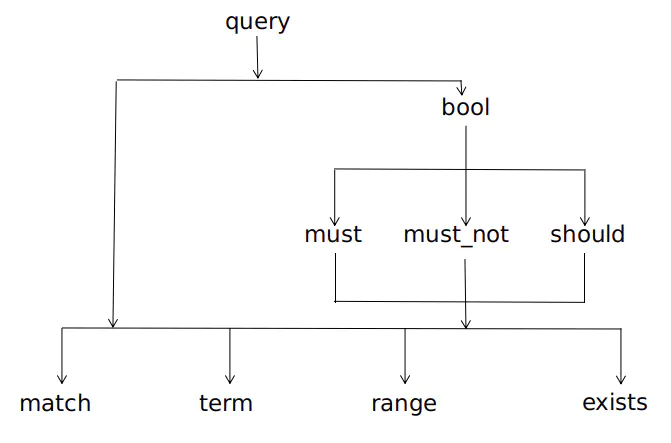
请求示例:
POST /bank/_search
{
"query": {
"match_all": {}
},
"sort":[
{
"account_number": "asc"
},
{
"balance": "desc"
}
]
}ES把这种可以通过执行查询的 Json 风格的 DSL(domain-specific-language 领域特定语言),被称为 Query DSL。
3、精度控制搜索
1、针对analyzed字段进行精确查询
POST /test_index/_search
{
"query": {
"match": {
"title": {
"query": "人生苦短,我用python",
"minimum_should_match":"100%" // 精确匹配,需要指定匹配相似度
}
}
}
}match用法:
GET bank/_search
{
"query":{
"match": {
"address": "Kings"
}
}
}term用法:
和match 一样,匹配某个属性的值。全文检索字段用 match,其他非 text 字段匹配用 term。
全文检索按照评分进行排序,会对检索条件进行分词匹配。
4、 复杂查询
DSL:Domain Specific Language,ES提供一种基于JSON的查询语言,这种查询语言包含两种子句模式:
- 1.Leaf query clauses
- 2.Compound query clauses --常用的就是bool组合查询
Query一般来说包含两各部分:query context 或 filter context:
示例:
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "Search" }},
{ "match": { "content": "Elasticsearch" }}
],
"filter": [
{ "term": { "status": "published" }},
{ "range": { "publish_date": { "gte": "2015-01-01" }}}
]
}
}
}这个例子的query就包含了所有2种context,并使用了bool组合查询,可以看到bool是最外围的关键字,must与filter并行。
bool组合查询的子关键字主要包含must,must_not,should,分别对应AND、NOT、OR三种逻辑运算,此外还有一个filter子关键字。
--filter与must:match的区别:
参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-bool-query.html
1.must:match会为匹配到的每个记录打分,称作scoring,表示匹配程度,查询的结果按打分进行排序。
2.filter与must:match基本一致,唯一的区别是其结果不参与打分,相当于一个再过滤。
三、项目实战
商品检索,根据筛选条件查
GET gulimall_product/_search
{
"query":{
"bool": {
"must": [
{"match": {
"skuTitle": "华为"
}}
],
"filter": [
{
"term":{
"catalogId":"225"
}
},
{
"terms":{
"brandId":[
"1",
"2",
"4",
"9"
]
}
}
]
}
}
}查询结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.5753642,
"hits" : [
{
"_index" : "gulimall_product",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.5753642,
"_source" : {
"attrs" : [
{
"attrId" : 5,
"attrName" : "CPU",
"attrValue" : "麒麟800"
}
],
"brandId" : 4,
"brandImg" : "https://gulimall-corwien.oss-cn-heyuan.aliyuncs.com/2020-08-26/174563e7-65d8-40d8-80ed-3081bfd249fe_huawei.png",
"brandName" : "华为",
"catalogId" : 225,
"catalogName" : "手机",
"hasStock" : false,
"hotScore" : 0,
"saleCount" : 0,
"skuId" : 1,
"skuImg" : "https://gulimall-corwien.oss-cn-heyuan.aliyuncs.com/2020-08-26/54995f55-c35c-4711-8447-c2482336ae1e_8bf441260bffa42f.jpg",
"skuPrice" : 6999.0,
"skuTitle" : "华为P60 8G",
"spuId" : 5
}
}
]
}
}四、数据迁移
由于ElasticSearch没有像mysql一样可以直接字段数据类型的方法,因此需要通过创建中间索引:data_index_1,备份数据到中间索引:data_index_1,然后删除原索引: data_index,重新创建正确数据类型索引:data_index,再把中间索引:data_index_1的数据备份到新创建索引:data_index。语句通过kibana的 dev_tools/console 执行。
操作步骤如下:
- 创建一个中间索引
- 向中间索引备份源索引的数据(mapping)
- 查询确认数据是否copy过去
- 删除有问题的索引
- 重新创建同名的索引(★字段类型修改正确★)
- 从中间索引还原到源索引的数据
- 删除中间索引
代码示例:
# 1、获取索引的映射
GET gulimall_product/_mapping
# 2、创建中间索引(直接使用下边的)
# PUT gulimall_product_1/
# 3、创建索引,并且同时设置索引Mapping
PUT gulimall_product_2
{
"mappings": {
"properties": {
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword"
},
"attrValue": {
"type": "keyword"
}
}
},
"brandId": {
"type": "long"
},
"brandImg": {
"type": "keyword"
},
"brandName": {
"type": "keyword"
},
"catalogId": {
"type": "long"
},
"catalogName": {
"type": "keyword"
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"saleCount": {
"type": "long"
},
"skuId": {
"type": "long"
},
"skuImg": {
"type": "keyword"
},
"skuPrice": {
"type": "keyword"
},
"skuTitle": {
"type": "text"
},
"spuId": {
"type": "keyword"
}
}
}
}
# 4、查看创建的索引
GET gulimall_product_2
# 5、迁移数据
POST _reindex
{
"source": {
"index": "gulimall_product"
},
"dest": {
"index": "gulimall_product_2"
}
}
# 6、查询数据是否已迁移成功
GET gulimall_product_2/_search
# 7、上边迁移成功后,删除有问题的索引
DELETE gulimall_product
# 8、重新创建同名的索引(★字段类型修改正确★)
PUT gulimall_product
{
"mappings": {
"properties": {
"attrs": {
"type": "nested",
"properties": {
"attrId": {
"type": "long"
},
"attrName": {
"type": "keyword"
},
"attrValue": {
"type": "keyword"
}
}
},
"brandId": {
"type": "long"
},
"brandImg": {
"type": "keyword"
},
"brandName": {
"type": "keyword"
},
"catalogId": {
"type": "long"
},
"catalogName": {
"type": "keyword"
},
"hasStock": {
"type": "boolean"
},
"hotScore": {
"type": "long"
},
"saleCount": {
"type": "long"
},
"skuId": {
"type": "long"
},
"skuImg": {
"type": "keyword"
},
"skuPrice": {
"type": "keyword"
},
"skuTitle": {
"type": "text"
},
"spuId": {
"type": "keyword"
}
}
}
}
# 9、从中间索引还原到源索引的数据
POST _reindex
{
"source": {
"index": "gulimall_product_2"
},
"dest": {
"index": "gulimall_product"
}
}
# 10、再次查询数据是否已迁移成功
GET gulimall_product/_search
# 11、上边迁移成功后,删除中间索引
DELETE gulimall_product_2
相关文章:
Elasticsearch基本操作
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



