
Python Pandas DataFrame 加载数据 (二十三)
在机器学习中,你很有可能会使用来自很多来源的数据库训练学习算法。Pandas 使我们能够将不同格式的数据库加载到 DataFrame 中。用于存储数据库的最热门数据格式是 csv。
加载数据
CSV 是指逗号分隔值,是一种简单的数据存储格式。我们可以使用 pd.read_csv()函数将 CSV 文件加载到 Pandas DataFrame 中。我们将 Google 股票数据加载到一个 Pandas DataFrame 中。GOOG.csv 文件包含从雅虎金融那获取的 2004 年 8 月 19 日至 2017 年 10 月 13 日 Google 股票数据。
# 我们将 Google 股票数据加载到 DataFrame 中
Google_stock = pd.read_csv('./GOOG.csv')
# 我们输出关于 Google_stock 的一些信息
print('Google_stock is of type:', type(Google_stock))
print('Google_stock has shape:', Google_stock.shape)打印:
Google_stock is of type: class 'pandas.core.frame.DataFrame'
Google_stock has shape: (3313, 7)可以看出,我们将 GOOG.csv 文件加载到了 Pandas DataFrame 中,其中包含 3,313 行和 7 列数据。现在我们来看看股票数据
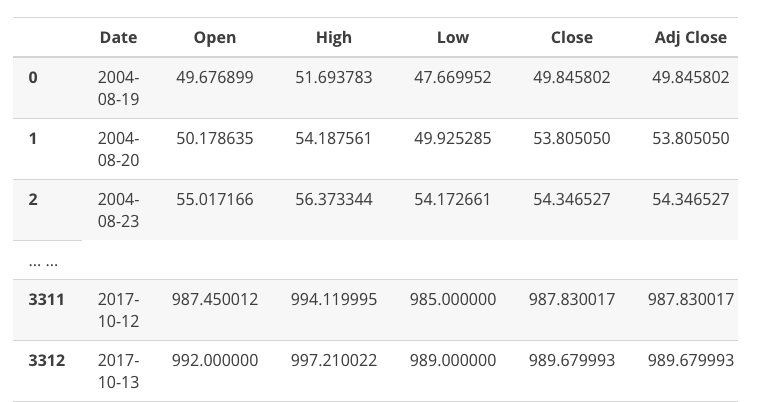
可以看出,这是一个非常庞大的数据集,Pandas 自动为该 DataFrame 分配了数字行索引。Pandas 还使用出现在 CSV 文件中的标签为列分配标签。
head()和tail()
在处理这样的大型数据集时,通常有必要直接查看前几行数据,而不是整个数据集。我们可以使用 .head() 方法查看前 5 行数据,如下所示
Google_stock.head()我们还可以使用 .tail()方法查看最后 5 行数据:
Google_stock.tail()我们还可以选择使用.head(N)或 .tail(N)分别显示前 N 行和后 N 行数据。
检查是否有NaN值
我们快速检查下数据集中是否有任何NaN 值。为此,我们将使用 .isnull()方法,然后是 .any()方法,检查是否有任何列包含 NaN 值。
Google_stock.isnull().any()打印:
Date False
Open False
High False
Low False
Close False
Adj Close False
Volume False
dtype: bool可以看出没有任何 NaN 值。
describe()获取统计信息
在处理大型数据集时,通常有必要获取关于数据集的统计信息。通过使用 Pandas 的 .describe() 方法,可以获取关于 DataFrame 每列的描述性统计信息。我们来看看代码编写方式:
# We get descriptive statistics on our stock data
Google_stock.describe()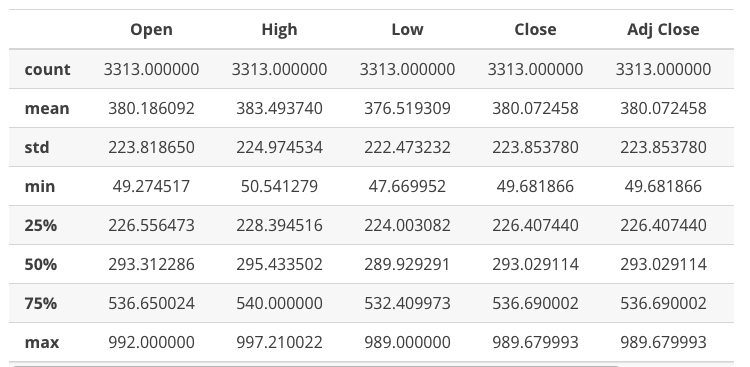
如果有必要,我们可以对单列应用 .describe()方法,如下所示:
# We get descriptive statistics on a single column of our DataFrame
Google_stock['Adj Close'].describe()打印:
count 3313.000000
mean 380.072458
std 223.853780
min 49.681866
25% 226.407440
50% 293.029114
75% 536.690002
max 989.679993
Name: Adj Close, dtype: float64统计函数
同样,你可以使用 Pandas 提供的很多统计学函数查看某个统计信息。我们来看一些示例:
# We print information about our DataFrame
print()
print('Maximum values of each column:\n', Google_stock.max())
print()
print('Minimum Close value:', Google_stock['Close'].min())
print()
print('Average value of each column:\n', Google_stock.mean())打印:
Maximum values of each column:
Date 2017-10-13
Open 992
High 997.21
Low 989
Close 989.68
Adj Close 989.68
Volume 82768100
dtype: object
Minimum Close value: 49.681866
Average value of each column:
Open 3.801861e+02
High 3.834937e+02
Low 3.765193e+02
Close 3.800725e+02
Adj Close 3.800725e+02
Volume 8.038476e+06
dtype: float64相关性corr()
另一个重要统计学衡量指标是数据相关性。数据相关性可以告诉我们不同列的数据是否有关联。我们可以使用 .corr()方法获取不同列之间的关联性,如下所示:
# We display the correlation between columns
Google_stock.corr()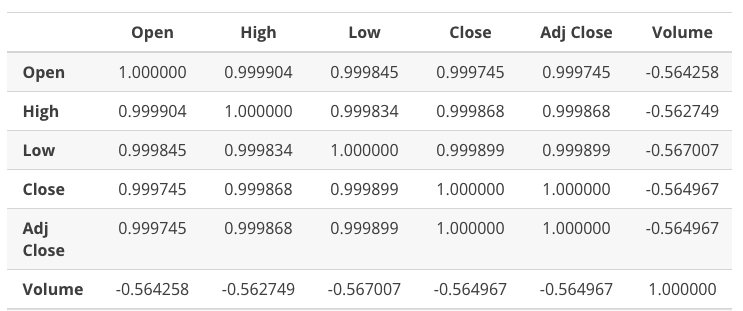
关联性值为 1 表明关联性很高,关联性值为 0 告诉我们数据根本不相关。
分组groupby()
分组求和
在这门“Pandas 入门”课程的最后,我们将讲解.groupby() 方法。.groupby()方法使我们能够以不同的方式对数据分组。我们来看看如何分组数据,以获得不同类型的信息。在下面的示例中,我们将加载关于虚拟公司的虚拟数据。
# We load fake Company data in a DataFrame
data = pd.read_csv('./fake_company.csv')
data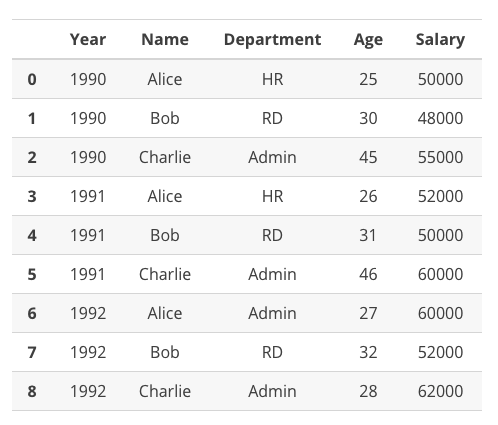
可以看出,上述数据包含从 1990 年到 1992 年的信息。对于每一年,我们都能看到员工姓名、所在的部门、年龄和年薪。现在,我们使用.groupby() 方法获取信息。
我们来计算公司每年在员工薪资上花费的数额。为此,我们将使用 .groupby()方法按年份对数据分组,然后使用 .sum() 方法将所有员工的薪资相加。
# We display the total amount of money spent in salaries each year
data.groupby(['Year'])['Salary'].sum()打印:
Year
1990 153000
1991 162000
1992 174000
Name: Salary, dtype: int64可以看出,该公司在 1990 年的薪资花费总额为 153,000 美元,在 1991 年为 162,000 美元,在 1992 年为 174,000 美元。
分组求平均值
现在假设我们想知道每年的平均薪资是多少。为此,我们将使用 .groupby() 方法按年份对数据分组,就像之前一样,然后使用 .mean()方法获取平均薪资。我们来看看代码编写方式
# We display the average salary per year
data.groupby(['Year'])['Salary'].mean()Year
1990 51000
1991 54000
1992 58000
Name: Salary, dtype: int64可以看出,1990 年的平均薪资为 51,000 美元,1991 年为 54,000 美元,1992 年为 58,000 美元。
现在我们来看看在这三年的时间内每位员工都收到多少薪资。在这种情况下,我们将使用.groupby()方法按照Name来对数据分组。之后,我们会把每年的薪资加起来。让我们来看看结果。
# We display the total salary each employee received in all the years they worked for the company
data.groupby(['Name'])['Salary'].sum()打印:
Name
Alice 162000
Bob 150000
Charlie 177000
Name: Salary, dtype: int64多个字段分组
现在让我们看看每年每个部门的薪资分配状况。在这种情况下,我们将使用.groupby()方法按照Year和Department对数据分组,之后我们会把每个部门的薪资加起来。让我们来看看结果。
# We display the salary distribution per department per year.
data.groupby(['Year', 'Department'])['Salary'].sum()打印:
Year Department
1990 Admin 55000
HR 50000
RD 48000
1991 Admin 60000
HR 52000
RD 50000
1992 Admin 122000
RD 52000
Name: Salary, dtype: int64为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


