
如何用 Apache Airflow 构建数据管道
数据管道(Data Pipelines)难以构建和管理,因此最好使用特定的工具来帮助我们完成任务。Apache Airflow是一个非常流行的开源管理工作流平台,在本文中,您将学习如何使用它来自动化第一个工作流。
本文假设您已经知道如何创建和运行Bash和Python脚本。本教程使用Ubuntu 20.04,并安装了ImageMagick,tesseract和Python3。
如何准备工作流
一个重要的概念是,您将仅使用Airflow来自动化和管理任务,因此必须设计工作流并将其分解为Bash或Python脚本。
我们先创建一个工作流并手动运行它,然后了解如何使用Airflow将其自动化。
自动执行的任务
在本教程中,我们从pdf文件中提取数据并将其保存到csv文件中。

主要任务:
- 1、从pdf文件中提取文本并将其保存在txt文件中。
- 2、从文本文件中提取所需的元数据并将其保存到csv文件。
要运行第一个任务,我们使用ImageMagick工具将pdf页面转换为png文件,然后使用tesseract将图像转换为txt文件,这些任务将在Bash脚本中定义。要提取元数据,我们使用Python和正则表达式。
1、从pdf文件中提取文本
Bash脚本的工作流程如下:
- 1、接收pdf文件名作为参数
- 2、将页面转换为png文件
- 3、将图像转换为txt文件
Bash脚本代码:
#!/bin/bash
PDF_FILENAME="$1"
convert -density 600 "$PDF_FILENAME" "$PDF_FILENAME.png"
tesseract "$PDF_FILENAME.png" "$PDF_FILENAME"将bash脚本命名为 pdf_to_text.sh,然后运行 chmod +x pdf_to_text.sh 并运行./pdf_to_text.sh pdf_filename 来创建txt文件。可在此处下载pdf文件。
2. 提取元数据并将其保存到csv
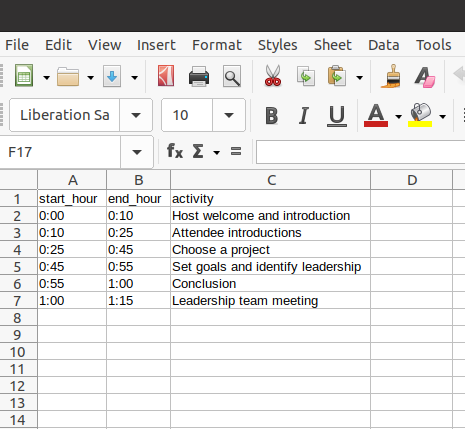
现在我们有了txt文件,是时候创建正则表达式来提取数据。目的是提取会议每个小时发生的事情。您可以通过使用一种模式来提取数据,该模式可以捕获小时数以及在此之后以及换行之前发生的事情。正则表达式模式:(d:dd)-(d:dd) (.*n)。
Python脚本代码:
import re
import csv
if __name__ == "__main__":
pattern = "(d:dd)-(d:dd) (.*n)"
with open('metadata.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(["start_hour","end_hour","activity"])
txt = open("extracted_text.txt", "r", encoding="ISO-8859–1").read()
extracted_data = re.findall(pattern,txt)
for data in extracted_data:
moment = [data[0].strip(),data[1].strip(),data[2].strip()]
writer.writerow(moment)将Python脚本命名为 extract_metadata.py,在终端运行 python3 extrac_metadata.py,得到 metadata.csv。
在本文中,我们不讨论创建工作流的最佳实践,如果您想了解更多信息,我强烈建议观看Airflow创始人的演讲: Functional Data Engineering – A Best Practices 。
什么是Airflow?
要使用Airflow,我们要运行Web服务器,通过浏览器访问UI。您可以安排作业以自动运行,因此,除了Web服务器之外,还需要运行任务调度程序。在生产环境中,我们通常在专用服务器上运行它,这里仅在本地运行。
先创建一个虚拟环境,然后运行以下命令来安装所有软件:
$ python3 -m venv .env
$ source .env/bin/activate
$ pip3 install apache-airflow
$ pip3 install cattrs==1.0.0. #I had to run this to work
$ airflow version # check if everything is ok
$ airflow initdb #start the database Airflow uses
$ airflow scheduler #start the scheduler打开另一个终端窗口并运行Web服务器:
$ source .env/bin/activate
$ airflow webserver -p 8080在浏览器打开https://localhost:8080,进入监控任务流的前端UI。
创建第一个DAG
Airflow使用DAG(有向无环图)定义工作流。DAG是一个Python脚本,用于定义和配置任务,同时处理任务依赖,查看官方文档以了解更多细节。
Airflow使用Operators 定义任务。常用的Operators有BashOperators(用于执行bash命令),PythonOperators(执行Python函数),MySqlOperators(执行SQL命令)等等。在本教程中我们仅使用BashOperator。
运行工作流时,Airflow会创建DAG Run,该对象表示DAG在时间上的实例。为简单起见,我们手动触发DAG而不使用调度程序。
让我们创建 first_dag.py 以了解如何将这些元素结合在一起。
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'Déborah Mesquita',
'start_date': days_ago(1)
}
# Defining the DAG using Context Manager
with DAG(
'extract-meeting-activities',
default_args=default_args,
schedule_interval=None,
) as dag:
t1 = BashOperator(
task_id = 'extract_text_from_pdf',
bash_command = 'YOUR-LOCAL-PATH/airflow-tutorial/pdf_to_text.sh {{ dag_run.conf["working_path"] if dag_run else "" }} {{ dag_run.conf["pdf_filename"] if dag_run else "" }}',
)
t2 = BashOperator(
task_id = 'extract_metadata_from_text',
bash_command = 'python3 YOUR-LOCAL-PATH/airflow-tutorial/extract_metadata.py {{ dag_run.conf["working_path"] if dag_run else "" }}',
)
t1 >> t2 # Defining the task dependencies我们要在 default_args 字典中指定两个参数,所有者(owner)和开始日期(start_date)。然后使用上下文管理器实例化DAG对象。第一个参数是DAG的名称( extract-meeting-activities ),然后传递default_args并将schedule_interval设置为None,因为我们将手动触发工作流。
接下来创建具体的任务,在此工作流中,我们使用BashOperator运行之前创建的bash和python脚本。
还记得第一个脚本接收pdf文件名作为参数吗?在DAG中,我们可以在触发工作流时传递参数,参数存储在dag_run.conf 字典中,可以使用键(key)访问它们。
为了使工作流按预期运行,需要对脚本进行一些更改。当Airflow运行脚本时,它将在一个临时目录中运行,这与我们手动运行脚本的目录不同。因此我们传递包含pdf文件的PATH,该路径与最终生成的csv的文件路径相同。您可以在该Github仓库中查看最终脚本。
最后使用位移运算符 >> 定义任务依赖,先运行t1(bash脚本),再运行t2(python脚本)。
运行DAG
默认情况下,Airflow会扫描目录~/airflow/dags 以寻找DAG。由于我们没有更改Airflow配置,只需要将first_dag.py复制到该目录即可。
$ cp first_dag.py ~/airflow/dags/访问https://localhost:8080 ,可以看到DAG。
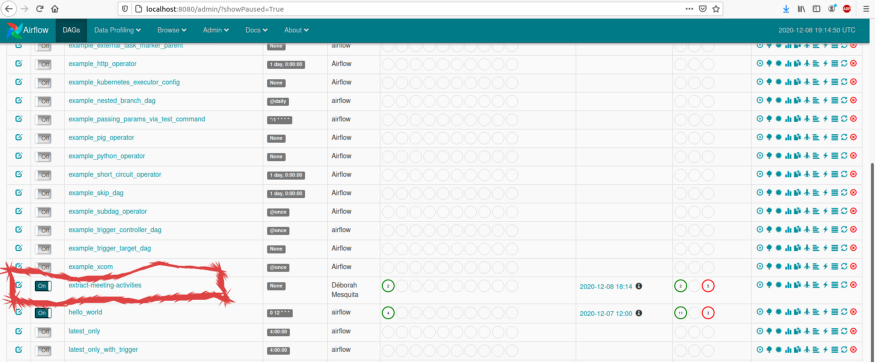
要触发DAG,先单击DAG名称( extract-meeting-activities ),然后点“Trigger DAG”:
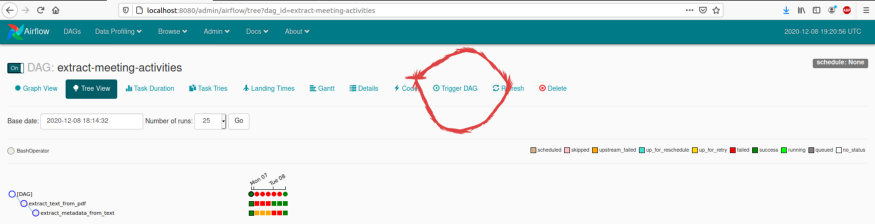
在文本框中传递参数,然后点触发按钮。参数如下:
{"working_path": "YOUR-LOCAL-PATH/airflow-tutorial/",
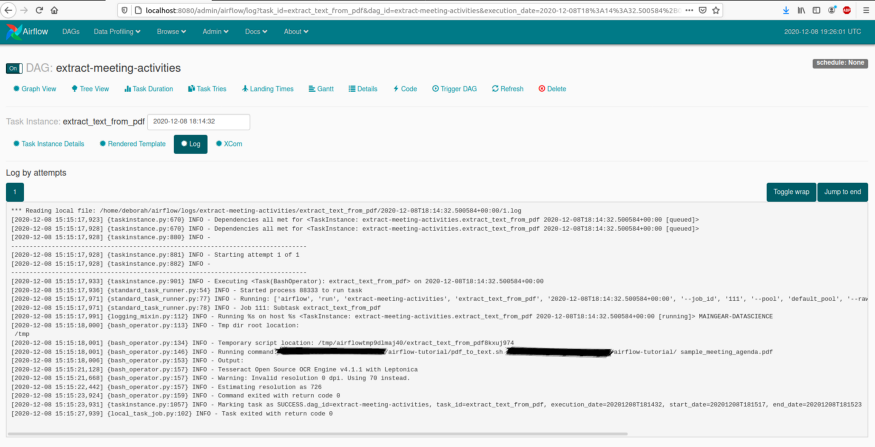
"pdf_filename": "sample_meeting_agenda.pdf"}然后进入“树视图(Tree View)”页面,可以看到DAG的运行情况。绿色表示一切正常,红色表示任务已失败,黄色表示任务尚未运行且可以重试。点击“View Log”可以检查每个任务的日志。
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



