
大数据之 Hadoop-13-HBase
一、HBase简介
1、HBase是什么
Apache HBase是一个开源的、分布式的、非关系型的列式数据库。
HBase位于 Hadoop生态系统的结构化存储层,数据存储于分布式文件系统HDFS并且使用ZooKeeper作为协调服务。HDFS为HBase提供了高可靠性的底层存储支持,MapReduce为 HBase提供了高性能的计算能力,ZooKeeper则为HBase提供了稳定的服务和失效恢复机制。
HBase的设计目的是处理非常庞大的表,甚至可以使用普通计算机处理超过10亿行的、由数百万列组成的表的数据。由于 HBase依赖于Hadoop HDFS,因此它与Hadoop一样,主要依靠横向扩展,并不断增加廉价的商用服务器来提高计算和存储能力。
HBase对表的处理具有如下特点:
- 一个表可以有上亿行、上百万
- 采用面向列的存储和权限控制。
- 为空(NULL)的列并不占用存储空间。
2、HBase基本结构
HBase数据库的基本组成结构如下:
1.表( table)
在HBase中,数据存储在表中,表名是一个字符串 (String),表由行和列组成。与关系型数据库(RDBMS)不同,HBase表是多维映射的。
2.行( row)
HBase中的行由行键(rowkey)和一个或多个列(column)组成。行键没有数据类型,总是视为字节数组 byte[]。行键类似于关系型数据库(RDBMS)中的主键索引,在整个 HBase表中是唯一的,但与RDBMS 不同的是,行键按照字母顺序排序。
3.列族(column family)
HBase列族由多个列组成,相当于将列进行分组。列的数量没有限制,一个列族里可以有数百万个列。表中的每一行都有同样的列族。列族必须在表创建的时候指定,不能轻易修改,且数量不能太多,一般不超过3个。列族名的类型是字符串(String) 。
4.列限定符( qualifier)
列限定符用于代表 HBase 表中列的名称,列族里的数据通过列限定符来定位,常见的定位格式为“family:qualifier”(例如,要定位到列族cf1中的列name,则使用 cf1:name)。HBase中的列族和列限定符都可以理解为列,只是级别不同。一个列族下面可以有多个列限定符,因此列族可以简单地理解为第一级列,列限定符是第二级列,两者是父子关系。与行键
-样,列限定符没有数据类型,总是视为字节数组byte[]。
5.单元格( cell)
单元格通过行键、列族和列限定符一起来定位。单元格包含值和时间戳。值没有数据类型,总是视为字节数组byte[],时间戳代表该值的版本,类型为long。默认情况下,时间戳表示数据写入服务器的时间,但是当数据放入单元格时,也可以指定不同的时间戳。每个单元格都根据时间戳保存着同一份数据的多个版本,且降序排列,即最新的数据排在前面,这样有利于快速查找最新数据。对单元格中的数据进行访问的时候会默认读取最新的值。
3、数据模型
下图可视化的方式展现了 RDBMS(关系型数据库) 和 HBase 的数据模型的不同。


二、HBase集群架构
HBase 架构采用主从( master/slave)方式,由三种类型的节点组成—— HMaster节点、HRegionServer节点和ZooKeeper集群。HMaster节点作为主节点,HRegionServer节点作为从节点,这种主从模式类似于HDFS的NameNode 与DataNode。
HBase集群中所有的节点都是通过ZooKeeper来进行协调的。HBase 底层通过HRegionServer将数据存储于HDFS 中。HBase集群部署架构如下图所示。

HBase 集群部署架构
HBase客户端通过RPC 方式与 HMaster节点和 HRegionServer节点通信,HMaster 节点连接ZooKeeper获得HRegionServer节点的状态并对其进行管理。HBase 的系统架构如下图所示。

HBase 系统架构
三、安装配置
HBase有 单机模式、伪分布模式、集群模式三种安装方式,为了和实战相近,我们这里只演示集群模式安装。
HBase集群建立在Hadoop集群的基础上,而且依赖于ZooKeeper,因此在搭建HBase集群之前,需要将Hadoop集群和ZooKeeper集群搭建好。Hadoop和 ZooKeeper集群的搭建在之前的博客有讲,此处不再赘述。
本例仍然使用三个节点(centos01、centos02、centos03)搭建部署HBase集群,搭建步骤如下。
1、下载解压
Hadoop和HBase版本关系: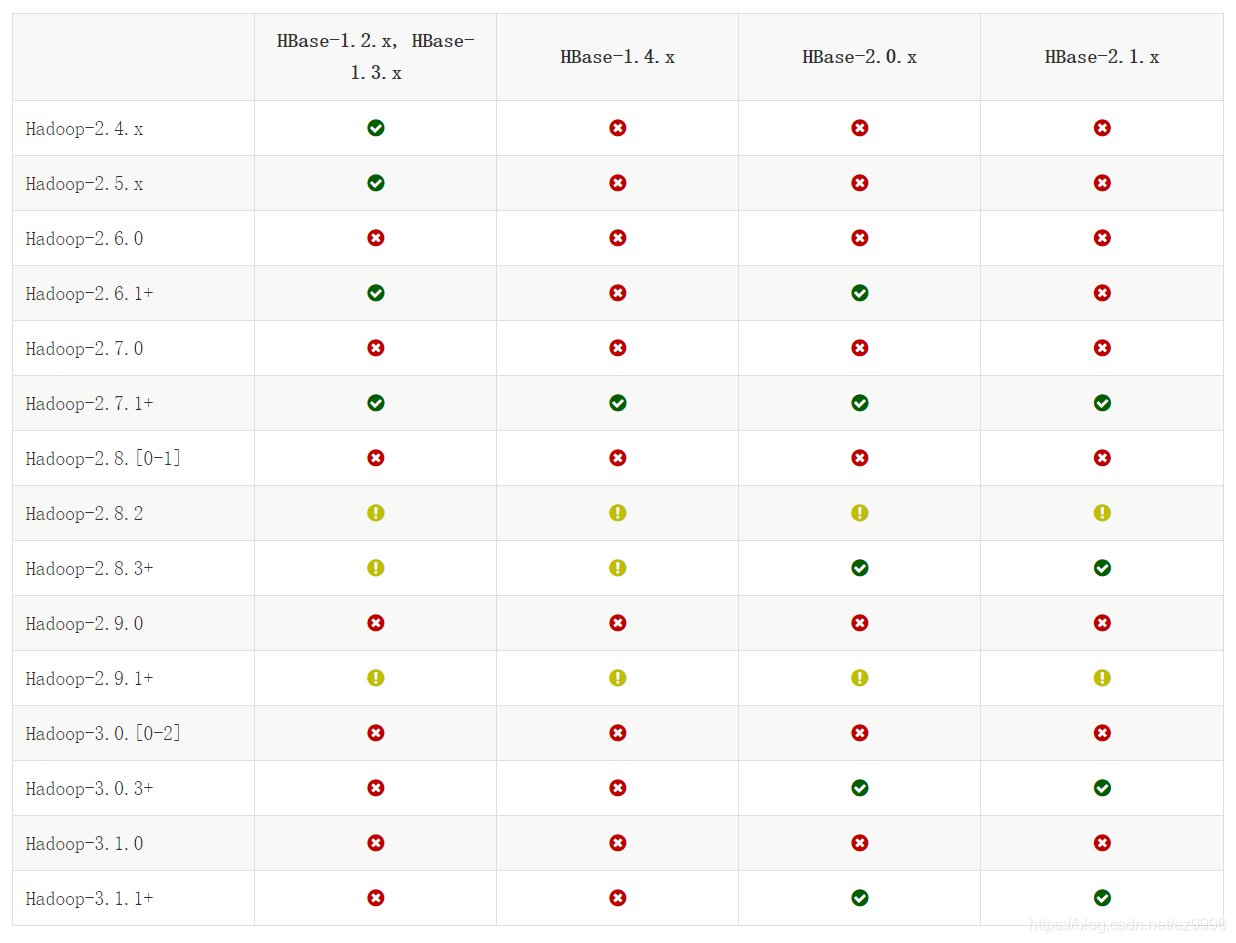
由于本地Hadoop版本为 hadoop-3.1.3, 所以对应的 HBase 版本为 HBase-2.1.x。
到清华镜像 mirrors.tuna.tsinghua.edu.cn 找到 HBase ,然后找到 HBase-2.1.x 地址下载,由于没有 2.1的版本,找 hbase-2.2.7 版本的下载。
$ cd /opt/softwares
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.2.7/hbase-2.2.7-bin.tar.gz
$ tar -zxvf hbase-2.2.7-bin.tar.gz -C /opt/modules/查看
$ cd /opt/modules/hbase-2.2.7
[root@centos01 hbase-2.2.7]# ls -l
总用量 1000
drwxr-xr-x. 4 root root 4096 1月 22 2020 bin
-rw-r--r--. 1 root root 218256 1月 22 2020 CHANGES.md
drwxr-xr-x. 2 root root 208 1月 22 2020 conf
drwxr-xr-x. 7 root root 80 1月 22 2020 hbase-webapps
-rw-rw-r--. 1 root root 262 1月 22 2020 LEGAL
drwxr-xr-x. 6 root root 8192 9月 16 07:36 lib
-rw-rw-r--. 1 root root 129312 1月 22 2020 LICENSE.txt
-rw-rw-r--. 1 root root 520609 1月 22 2020 NOTICE.txt
-rw-r--r--. 1 root root 1477 1月 22 2020 README.txt
-rw-r--r--. 1 root root 121393 1月 22 2020 RELEASENOTES.md
2、配置
2.1 hbase-env.sh 文件配置
修改HBase安装目录下的 conf/hbase-env.sh,配置HBase关联的JDK,加入以下代码;
export JAVA_HOME=/opt/modules/jdk1.8.0_2112.2 hbase-site.xml 文件配置
修改HBase安装目录下的 conf/hbase-site.xml,完整配置内容如下:
<configuration>
<!--需要与HDFS NameNode端口一致-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://centos01:9000/hbase</value>
</property>
<!--开启分布式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--ZooKeeper节点列表-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>centos01,centos02,centos03</value>
</property>
<!--ZooKeeper数据存放目录-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/modules/hbase-2.2.7/zkData</value>
</property>
</configuration>
完整文件:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--
The following properties are set for running HBase as a single process on a
developer workstation. With this configuration, HBase is running in
"stand-alone" mode and without a distributed file system. In this mode, and
without further configuration, HBase and ZooKeeper data are stored on the
local filesystem, in a path under the value configured for `hbase.tmp.dir`.
This value is overridden from its default value of `/tmp` because many
systems clean `/tmp` on a regular basis. Instead, it points to a path within
this HBase installation directory.
Running against the `LocalFileSystem`, as opposed to a distributed
filesystem, runs the risk of data integrity issues and data loss. Normally
HBase will refuse to run in such an environment. Setting
`hbase.unsafe.stream.capability.enforce` to `false` overrides this behavior,
permitting operation. This configuration is for the developer workstation
only and __should not be used in production!__
See also https://hbase.apache.org/book.html#standalone_dist
-->
<!-- 开启集群 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>./tmp</value>
</property>
<!--需要与HDFS NameNode端口一致-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://centos01:9000/hbase</value>
</property>
<!--ZooKeeper节点列表-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>centos01,centos02,centos03</value>
</property>
<!--ZooKeeper数据存放目录-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/modules/hbase-2.2.7/zkData</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
2.3 regionservers 文件配置
regionservers文件列出了所有运行HRegionServer进程的服务器。
本例中,我们将三个节点都作为运行HRegionServer的服务器。因此,我们需要作出如下修改:
修改HBase安装目录下的 /conf/regionservers 文件,去掉默认的 localhost,加入如下内容(注意:主机名前后不要包含空格):
centos01
centos02
centos033、复制HBase到其他节点
centos01节点配置完成后,需要复制整个HBase 安装目录文件到集群的其他节点,复制命令如下:
$ scp -r hbase-2.2.7/ hadoop@centos02:/opt/modules/
$ scp -r hbase-2.2.7/ hadoop@centos03:/opt/modules/注意:hadoop用户的密码为hadoop@123,root用户密码为:123456
4、启动与测试
启动HBase集群之前,需要先启动Hadoop集群。由于HBase不依赖Hadoop YARN,因此只启动Hadoop HDFS 即可。
在 centos01节点执行以下命令,启动HDFS:
[root@centos01 ~]# su hadoop
[hadoop@centos01 root]$ cd /opt/modules/hadoop-3.1.3
[hadoop@centos01 hadoop-3.1.3]$ sbin/start-dfs.sh在centos01节点执行以下命令,启动HBase集群。启动HBase集群的同时,会将ZooKeeper集群也同时启动。
$ cd /opt/modules/hbase-2.2.7
$ bin/start-hbase.sh启动完成后,查看个节点java进程:
[root@centos01 hadoop-3.1.3]# jps
9712 Jps
7568 NameNode
9222 HMaster
9527 HRegionServer
7692 DataNode
7903 SecondaryNameNode
[root@centos02 ~]# jps
7504 HQuorumPeer
7786 HRegionServer
7933 Jps
[root@centos03 ~]# jps
7570 HQuorumPeer
7428 DataNode
7836 Jps
四、HBase Shell命令操作
在启动HBase 之后,我们可以通过执行以下命令启动HBase Shell:
$ [root@centos01 hbase-2.2.7]# bin/hbase shell
hbase(main):001:0> 4.1 创建表
执行 create 't1',f1' 命令,将在HBase中创建一张表名为 t1,列族名为 f1 的表,命令及返回信息如下:
hbase(main):001:0> create 't1','f1'
Created table t1
Took 1.9855 seconds
=> Hbase::Table - t1注意:创建表的时候需要指定表名与列族名,列名在添加数据的时候动态指定。
4.2 添加数据
向表t1中添加一条数据,rowkey为row1,列name的值为zhangsan。命令如下:
hbase(main):002:0> put 't1','row1','f1:name','wenying'
Took 1.5048 seconds 4.3 全表扫描
hbase(main):003:0> scan 't1'
ROW COLUMN+CELL
row1 column=f1:name, timestamp=1631753479147, value=wenying
1 row(s)
Took 0.1797 seconds 查询一行数据
hbase(main):004:0> get 't1','row1'
COLUMN CELL
f1:name timestamp=1631753479147, value=wenying
1 row(s)
Took 0.0679 seconds 修改、删除表
hbase(main):004:0> get 't1','row1'
COLUMN CELL
f1:name timestamp=1631753479147, value=wenying
1 row(s)
Took 0.0679 seconds
hbase(main):005:0> put 't1','row1','f1:name','lily'
Took 0.0196 seconds
hbase(main):006:0> scan 't1'
ROW COLUMN+CELL
row1 column=f1:name, timestamp=1631753658724, value=lily
1 row(s)
Took 0.0162 seconds
hbase(main):007:0> delete 't1','row1','f1:name'
Took 0.0448 seconds
hbase(main):008:0> scan 't1'
ROW COLUMN+CELL
row1 column=f1:name, timestamp=1631753479147, value=wenying
1 row(s)
Took 0.0343 seconds 五、实战
HBase与Hive整合
我们已经知道,HBase数据库没有类SQL 的查询方式,因此在实际的业务中操作和计算数据非常不方便。而 Hive支持标准的SQL语法(HiveQL),若将Hive与 HBase整合,则可以通过HiveQL直接对HBase的表进行读写操作,让HBase支持JOIN、GROUP等SQL查询语法,完成复杂的数据分析。甚至可以通过连接和联合将对HBase表的访问与Hive表的访问结合起来进行统计与分析。
Hive与 HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作由Hive安装主目录下的lib文件夹中的hive-hbase-handler-x.y.z.jar工具类来实现。
Hive与 HBase整合的核心是将Hive中的表与HBase中的表进行绑定,绑定的关键是HBase中的表如何与Hive中的表在列级别上建立映射关系。
具体实现请参考上篇文章:大数据之 Hadoop-12-2-Hive 表操作、查询及实战
相关文章:
大数据之 Hadoop-12-2-Hive 表操作、查询及实战
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


