
Python:matplotlib 之标尺和变换 (三十一)
标尺和变换
某些数据分布可以进行标尺变换。最常见的示例是近似符合对数正态分布的数据。即采用原始单位的话,看起来非常偏态:很多数据点的值很小,有一个很长的尾部,尾部数据点的值很大。但是对这些值取对数的话,数据看起来是正态分布的。
plt.figure(figsize = [10, 5])
# histogram on left: natural units
plt.subplot(1, 2, 1)
bin_edges = np.arange(0, ln_data.max()+100, 100)
plt.hist(ln_data, bins = bin_edges)
# histogram on right: directly log-transform data
plt.subplot(1, 2, 2)
log_ln_data = np.log10(ln_data)
log_bin_edges = np.arange(0.8, log_ln_data.max()+0.1, 0.1)
plt.hist(log_ln_data, bins = log_bin_edges)
plt.xlabel('log(values)') # add axis label for clarity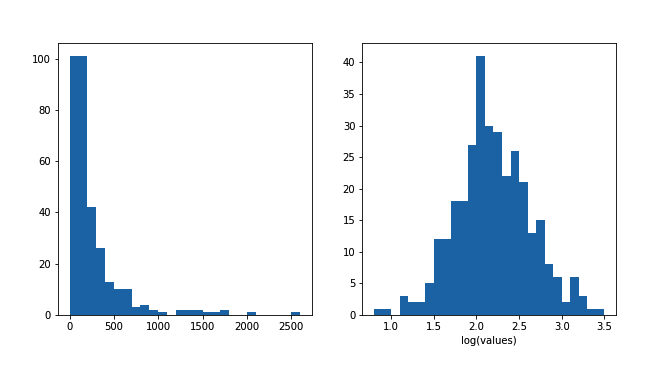
在左图中,超过 1000 的很高的值将大部分数据点推到了最左侧的分箱中。对于右图,对数变换将这些数据点看起来和剩余的数据点保持一致,整个数据看起来是单峰的。右图的最大问题是 x 轴的单位很难解释:对于很多人来说,他们只会相对娴熟地将整数的对数值转换为原始值(假设示例中的基数是 如10 等相对比较好算的值)。
这时候标尺变换就派上用场了。在标尺变换中,值之间的空隙基于变换的标尺,但是你可以用变量的原始单位解释数据。此外,你不需要设定新的特征,这很方便。Matplotlib 的 xscale 函数包含几个内置的变换:我们将使用 "对数" 标尺。
bin_edges = np.arange(0, ln_data.max()+100, 100)
plt.hist(ln_data, bins = bin_edges)
plt.xscale('log')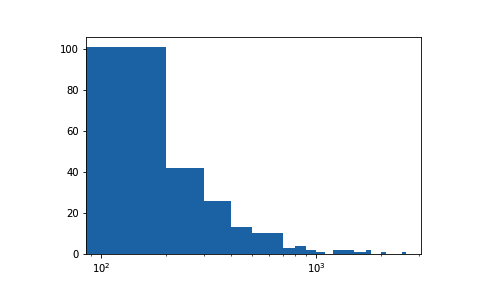
对于该图,注意两点:首先,即使数据采用的是对数标尺,分箱依然呈线性分布。意味着它们的尺寸从左到右由宽变窄,因为值会以倍数增大。其次,默认的标签设置依然很难解释,并且是稀疏的。
要处理分箱尺寸问题,我们只需将它们变成 10 的各次幂并且均匀分布。根据你所绘制的数据,2 次幂等其他次幂可能更合适。对于刻度,我们可以使用 xticks 以原始单位指定位置和标签。注意:我们并没有更改数据的值,只是改变了显示方式。在 10 次幂的整数之间,我们没有表示均匀刻度的整数,但是可以很接近。对于 10 次幂对数变换,设置 1-3-10 或 1-2-5-10 这样的循环刻度很有用。
bin_edges = 10 ** np.arange(0.8, np.log10(ln_data.max())+0.1, 0.1)
plt.hist(ln_data, bins = bin_edges)
plt.xscale('log')
tick_locs = [10, 30, 100, 300, 1000, 3000]
plt.xticks(tick_locs, tick_locs)请务必在 xscale 之后指定 xticks,因为该函数具有内置的刻度设置。
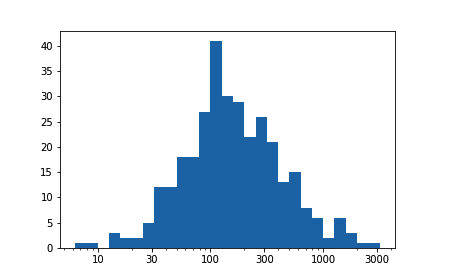
我们获得了和进行直接对数变换时得出的图形一样的图形,但是现在的刻度和标签看起来美观多了。
替代方法
注意,对数变换并不是唯一的变换方式。在进行对数变换时,数据值必须全是正数;0 或负数无法取对数。此外,对数变换表明对对数标尺进行加法将导致原始标尺出现倍数变化,这是在数据建模时需要注意的重要事项。你可以根据数据判断该选择什么类型的变换。例如,这篇维基百科文章的此部分介绍了几个运用对数正态分布的示例场合。
如果你想使用 xscale 中未提供的其他变换,则需要进行某些特征工程。在这种情形下,我们需要写一个应用变换和还原过程的函数,以保持系统性。当我们用变换单位指定值,并且需要获得以原始单位计量的值时,还原功能就很有用。为了进行演示,假设我们想要以平方根变换的形式绘制上述数据。(或许这些数字表示面积,我们认为有必要按照半径、长度或其他一维近似值来对数据建模)。我们可以如下所示地绘制变换后的分布情况:
def sqrt_trans(x, inverse = False):
""" transformation helper function """
if not inverse:
return np.sqrt(x)
else:
return x ** 2
bin_edges = np.arange(0, sqrt_trans(ln_data.max())+1, 1)
plt.hist(ln_data.apply(sqrt_trans), bins = bin_edges)
tick_locs = np.arange(0, sqrt_trans(ln_data.max())+10, 10)
plt.xticks(tick_locs, sqrt_trans(tick_locs, inverse = True).astype(int))注意 ln_data 是一个 pandas Series,因此我们可以使用该函数的 apply方法。如果是 NumPy 数组,则需要像在其他情形下一样应用该函数。刻度位置也应该用原始值指定,我们对 xticks 的第一个参数应用标准变换函数。
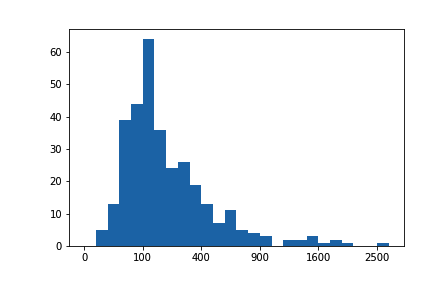
练习
# prerequisite package imports
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
from solutions_univ import scales_solution_1, scales_solution_2对于这道练习,我们将再次使用 Pokémon 数据。
pokemon = pd.read_csv('./data/pokemon.csv')
pokemon.head()| id | species | generation_id | height | weight | base_experience | type_1 | type_2 | hp | attack | defense | speed | special-attack | special-defense | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | bulbasaur | 1 | 0.7 | 6.9 | 64 | grass | poison | 45 | 49 | 49 | 45 | 65 | 65 |
| 1 | 2 | ivysaur | 1 | 1.0 | 13.0 | 142 | grass | poison | 60 | 62 | 63 | 60 | 80 | 80 |
| 2 | 3 | venusaur | 1 | 2.0 | 100.0 | 236 | grass | poison | 80 | 82 | 83 | 80 | 100 | 100 |
| 3 | 4 | charmander | 1 | 0.6 | 8.5 | 62 | fire | NaN | 39 | 52 | 43 | 65 | 60 | 50 |
| 4 | 5 | charmeleon | 1 | 1.1 | 19.0 | 142 | fire | NaN | 58 | 64 | 58 | 80 | 80 | 65 |
任务 1:数据集中的某些变量与游戏机制没有任何联系,只是提供一些干扰性信息。尝试绘制出 Pokémon 高度(米)的分布情况。对于这道练习,请尝试不同的坐标轴范围和分箱宽度,看看哪些设置能最清晰地呈现数据。
# YOUR CODE HERE
bin_edges = np.arange(0, pokemon['height'].max() + 0.2, 0.2)
#print(bin_edges)
plt.hist(data=pokemon, x='height', bins=bin_edges)
plt.xlim(0,6)(0, 6)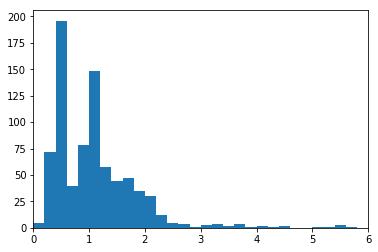
# run this cell to check your work against ours
scales_solution_1()There's a very long tail of Pokemon heights. Here, I've focused in on Pokemon of height 6 meters or less, so that I can use a smaller bin size to get a more detailed look at the main data distribution.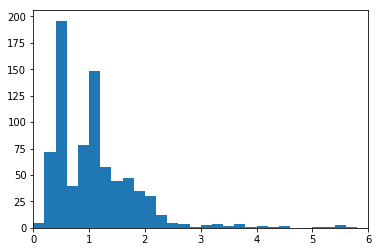
任务 2:在此练习中,你应该绘制 Pokémon 体重(千克)的分布情况。由于值的范围很广,你可能需要进行坐标轴变换。
# YOUR CODE HERE
log_ln_data = np.log10(pokemon['weight'])
log_bin_edges = np.arange(0, log_ln_data.max()+0.1, 0.1)
plt.hist(log_ln_data, bins = log_bin_edges)
plt.xlabel('log(values)') # add axis label for clarityText(0.5,0,'log(values)')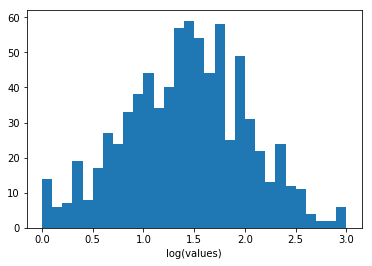
# run this cell to check your work against ours
scales_solution_2()Since Pokemon weights are so skewed, I used a log transformation on the x-axis. Bin edges are in increments of 0.1 powers of ten, with custom tick marks to demonstrate the log scaling.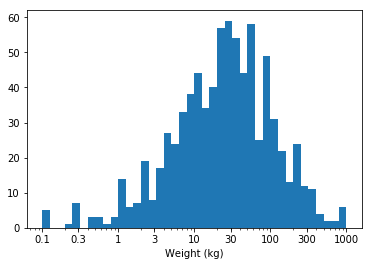
# YOUR CODE HERE
bin_edges = 10 ** np.arange(0, log_ln_data.max()+0.1, 0.1)
plt.hist(pokemon['weight'], bins = bin_edges)
plt.xlabel('log') # add axis label for clarity
tick_locs = [0, 50, 150, 300, 450, 600, 750, 1000]
plt.xticks(tick_locs, tick_locs)([<matplotlib.axis.XTick at 0x7f5489ec5cf8>,
<matplotlib.axis.XTick at 0x7f5489ec57b8>,
<matplotlib.axis.XTick at 0x7f5489e4e470>,
<matplotlib.axis.XTick at 0x7f5489e37e48>,
<matplotlib.axis.XTick at 0x7f5489e3f4e0>,
<matplotlib.axis.XTick at 0x7f5489e3fb38>,
<matplotlib.axis.XTick at 0x7f5489e441d0>,
<matplotlib.axis.XTick at 0x7f5489e44860>],
<a list of 8 Text xticklabel objects>)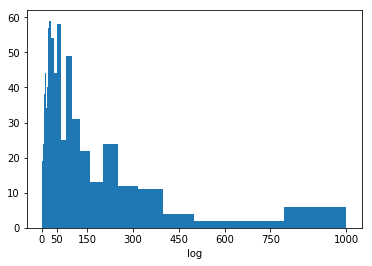
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



