
Python:matplotlib 和 Seaborn 之簇状柱形图、分面 (三十五)
簇状柱形图
为了描绘两个分类变量之间的关系,我们可以将在上节课见到的单变量条形图扩展为簇状柱形图。和标准条形图一样,我们依然需要描绘每组的数据点计数,但是每组现在是两个变量的标签组合。因此我们需要按照某种顺序整理长条,使图形容易解释。在簇状柱形图中,我们根据第一个变量的级别将长条分成一簇,然后在每个簇内根据第二个变量对长条进行排序。使用 seaborn 的 countplot 函数通过一个示例来讲解最容易理解。要使图形从单变量图形变成双变量图形,我们用 "hue" 参数添加第二个变量:
sb.countplot(data = df, x = 'cat_var1', hue = 'cat_var2')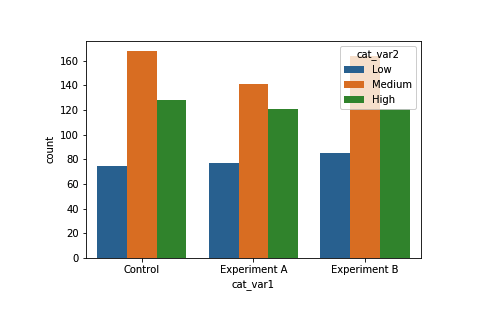
第一个分类变量用很宽泛的 x 轴表示(对照组、实验 A、实验 B)。在每组绘制三个长条,第二个分类变量的每个级别对应一个长条(低、中、高)。用颜色区分每个级别,并在图形的右上角用图例记录。图形告诉我们三个 "cat_var1" 群组在 "cat_var2" 级别的频率分布很平衡,虽然 "实验 A" 组与另外两组相比,中间点(橙色中心长条)的计数稍微低些。
但是,该示例中的图例位置有点干扰性。我们可以使用 Axes 方法设置 countplot 返回的 Axes 对象的 legend 属性。
ax = sb.countplot(data = df, x = 'cat_var1', hue = 'cat_var2')
ax.legend(loc = 8, ncol = 3, framealpha = 1, title = 'cat_var2')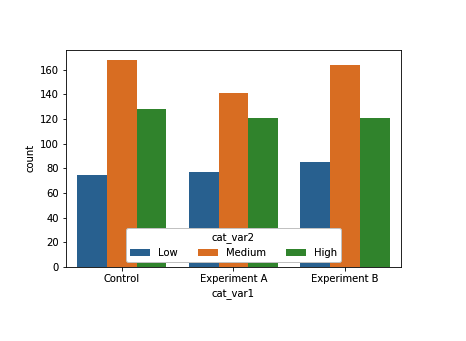
其他方法(热图)
描绘两个分类变量之间关系的另一种方式是热图。之前我们介绍热图是直方图的二维版本;现在我们将其当做条形图的二维版本。seaborn 函数 heatmap 可以轻松地实现这种类型的热图,但是输入参数与我们在这门课程中介绍的大部分可视化函数不一样。我们需要将计数总结为矩阵,然后进行绘制,而不是提供原始 dataframe。
ct_counts = df.groupby(['cat_var1', 'cat_var2']).size()
ct_counts = ct_counts.reset_index(name = 'count')
ct_counts = ct_counts.pivot(index = 'cat_var2', columns = 'cat_var1', values = 'count')sb.heatmap(ct_counts)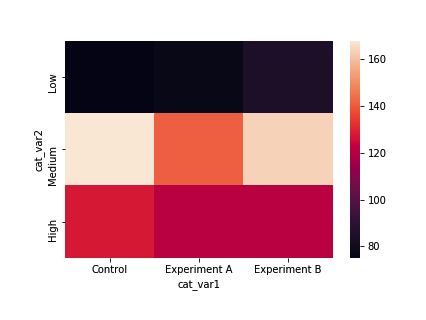
热图和簇状柱形图传达的信息一样:行上的相似颜色表示 "cat_var1" 群组的大小相似,并且在 "cat_var2" 级别上的分布相似。实验 A 的中间观测值的数量稍微少些,而对照组的高级别数据点的数量多些,实验 B 的低级别数据点的数量稍微多些。但是与簇状柱形图相比,差别大小的描绘不够精确。因此,我们可能需要在图形中添加注释,注明每个单元格的计数。
sb.heatmap(ct_counts, annot = True, fmt = 'd')annot = True 可以在每个单元格中显示注释,但是默认的字符串格式精度只能达到小数点后两位。添加 fmt = 'd' 表示注释将全变成整数形式。
分面
处理包含两个或多个变量的图形的一种实用方式是分面。采用分面技巧时,数据被划分为不相交的子集,通常根据分类变量的不同级别进行划分。对于每个子集,对其他变量采用相同的图形。分面是比较其他变量的不同级别分布和关系的一种方式,尤其是总共有三个或多个变量需要考虑时。虽然分面最适合多变量图形,但是依然有必要在我们的双变量图形中讨论这一技巧。
例如,我们不再使用小提琴图或箱线图描绘一个数字变量和一个分类变量之间的关系,而是使用分面描绘按照分类变量级别划分的子集数据的数字变量直方图。我们可以利用 Seaborn 的 FacetGrid 类创建分面图形。在创建分面图形时,需要完成两个步骤。首先,我们需要创建一个 FacetGrid 对象的实例,并指定要分面的特征(在我们的示例中为“cat_var”)。然后对 FacetGrid 对象使用 map 方法,指定在每个子集中要绘制的图形类型和变量(在此例中针对“num_var”绘制直方图)。
g = sb.FacetGrid(data = df, col = 'cat_var')
g.map(plt.hist, "num_var")在 map 调用中,将绘图函数和变量设为位置参数。请勿设为关键字参数,例如 x = "num_var”,否则映射无法正常发挥作用。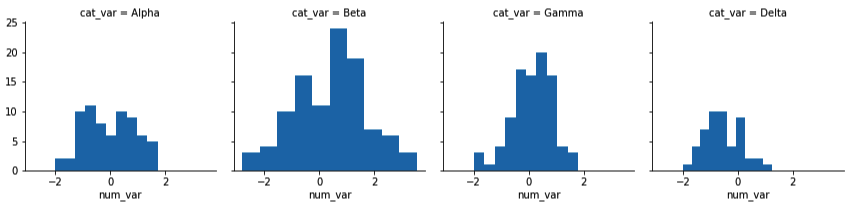
注意,每个子数据集都是独立绘制的。每个图形使用 hist 中的默认 10 个分箱划分数据,每个图形具有不同的分箱尺寸。但是,每个平面的坐标轴范围一样,以便清晰地直接对比每组。依然可以通过在所有平面设置相同的分箱边缘,使图形更整洁。可以在 map 函数中通过其他关键字参数设置其他可视化参数。
bin_edges = np.arange(-3, df['num_var'].max()+1/3, 1/3)
g = sb.FacetGrid(data = df, col = 'cat_var')
g.map(plt.hist, "num_var", bins = bin_edges)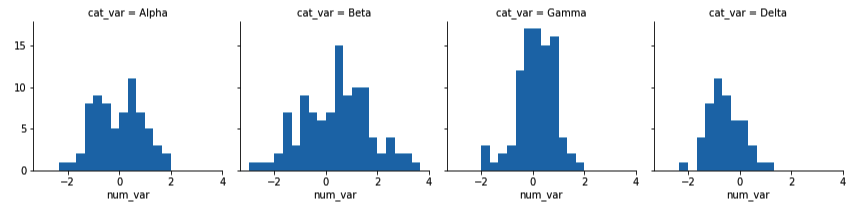
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



