
无人驾驶-08-一文读懂 BEVFormer 论文
本文是我阅读BEVFormer论文和开源工程后整理的一些内容,这里分享出来,便于大家进一步理解这个令人眼前“两亮”的工作。
1. References
开源工程:https://github.com/zhiqi-li/BEVFormer
参考中文解读
- 使用Transformer融合时空信息的自动驾驶感知框架
- 3d camera-only detection: BEVFormer
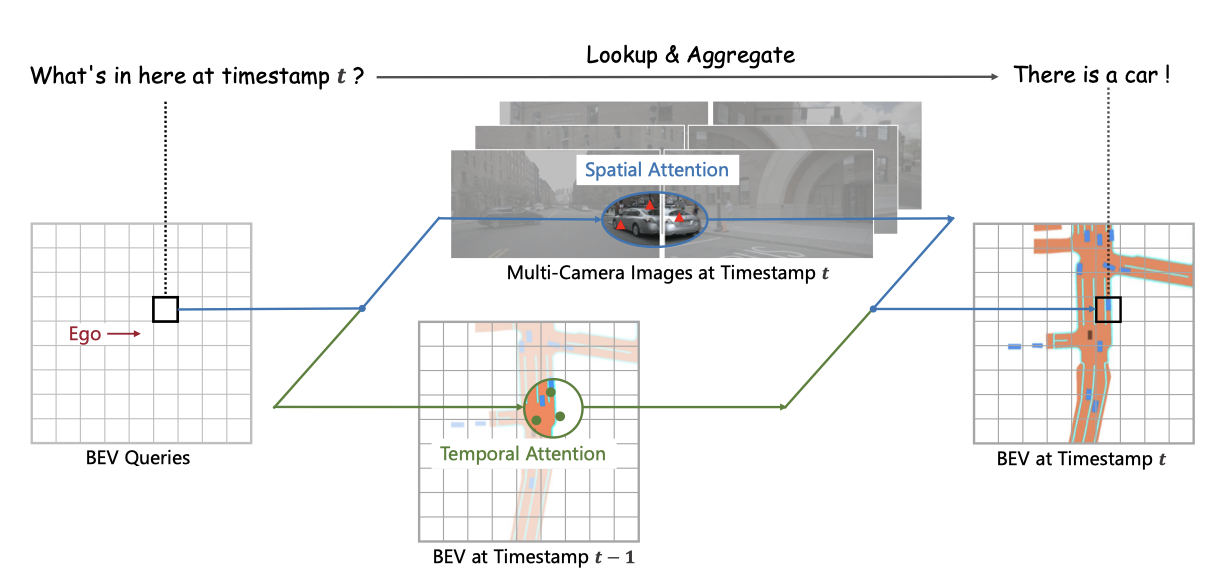
3 BEVFormer,通过一个时空Transformer学习 BEV表征
类似工作:
Cross-view Transformers for real-time Map-view Semantic Segmentation 论文:https://arxiv.org/pdf/2205.02833v1.pdf
代码:https://github.com/bradyz/cross_view_transformers/blob/master/requirements.txt
2. 背景/Motivation
2.1 为什么视觉感知要用BEV?
相机图像描述的是一个2D像素世界,然而自动驾驶中利用相机感知结果的后续决策、路径规划都是在车辆所处的3D世界下进行。由此引入的2D和3D维度不匹配,就导致基于相机感知结果直接进行自动驾驶变得异常困难。
这种感知和决策规划的空间维度不匹配的矛盾,也体现在学开车的新手上。倒车泊车时,新手通过后视镜观察车辆周围,很难直观地构建车子与周围障碍物的空间联系,容易导致误操作剐蹭或需要尝试多次才能泊车成功,本质上还是新手从2D图像到3D空间的转换能力较弱。基于相机图像平面感知结果进行决策规划的自动驾驶AI,就好比缺乏空间理解力的驾驶新手,很难把车开好。
实际上,利用感知结果进行决策和路径规划,问题还出现在多视角融合过程中:在每个相机上进行目标检测,然后对目标进行跨相机融合。如2021 TESLA AI Day给出的图1,带拖挂的卡车分布在多个相机感知野内,在这种场景下试图通过目标检测和融合来真实地描述卡车在真实世界中的姿态,存在非常大的挑战。

为了解决这些问题,很多公司采用硬件补充深度感知能力,如引入毫米波雷达或激光雷达与相机结合,辅助相机把图像平面感知结果转换到自车所在的3D世界,描述这个3D世界的专业术语叫做BEV map或BEV features(鸟瞰图或鸟瞰图特征),如果忽略高程信息,就把拍扁后的自车坐标系叫做BEV坐标系(即鸟瞰俯视图坐标系)。
相关文章:
知乎 | 一文读懂BEVFormer论文
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



