
Mac mini M4 Pro 48GB 本地大模型 + OpenClaw 完整部署指南
Mac mini M4 Pro 48GB 本地大模型 + OpenClaw 完整部署指南
适用硬件:Mac mini M4 Pro · 48GB 统一内存 · 512GB SSD
目标:零费用本地化运行 OpenClaw,替代 Kimi / MiniMax / Claude 等商用 API
更新时间:2026 年 3 月
目录
一、模型选型分析
M4 Pro 48GB 统一内存约 273 GB/s 内存带宽,是运行 32B 级别模型的理想硬件。针对 OpenClaw 的两个核心需求(coding + 多模态),推荐以下双模型组合:
主力模型:Qwen2.5-Coder 32B(coding 专用)
- 开源协议:Apache 2.0
- 参数量:32.5B,量化版(Q4_K_M)约 20GB
- 在 EvalPlus、LiveCodeBench、BigCodeBench 等主流代码基准上达到开源 SOTA,编码能力与 GPT-4o 相当
- 代码修复 Aider 基准得分 73.7,与 GPT-4o 持平
- 支持 40+ 编程语言,context window 最大 128K tokens
- HuggingFace:https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct
多模态模型:Qwen2.5-VL 7B(图像理解)
- 开源协议:Apache 2.0
- 参数量:7B,约 5GB
- 支持文档分析、图表解读、OCR、UI 截图理解、真实场景描述
- 在 macOS + Ollama 本地运行稳定,多类视觉任务表现出色
- HuggingFace:https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct
资源占用一览
| 模型 | 用途 | 量化 | 磁盘占用 | 运行内存 |
|---|---|---|---|---|
| qwen2.5-coder:32b-instruct-q4_K_M | 主力 coding agent | Q4_K_M | ~20GB | ~22GB |
| qwen2.5vl:7b | 多模态/图像理解 | Q4 | ~5GB | ~6GB |
两模型合计约 25GB 存储,同时热加载不超过 30GB 内存,512GB SSD 和 48GB 统一内存均充裕。
运行后端:Ollama
OpenClaw 与 Ollama 原生 API(/api/chat)深度集成,同时支持流式响应和工具调用(tool calling),是最简洁、最稳定的本地部署路径。
二、环境安装
第一步:安装 Homebrew(已有可跳过)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"第二步:安装 Ollama
brew install ollama验证安装:
ollama --version第三步:安装 Node.js
OpenClaw 基于 Node.js 运行,需要 v18 或更高版本。
brew install node验证:
node --version # 应显示 v18.x 或更高
npm --version第四步:安装 OpenClaw
npm install -g openclaw验证:
openclaw --version三、拉取并运行模型
启动 Ollama 服务
ollama serve
#OLLAMA_NUM_CTX=65536 ollama serve建议另开一个终端窗口继续操作,或参考第六节配置为开机自启服务。
拉取 Coding 主力模型
ollama pull qwen2.5-coder:32b-instruct-q4_K_M文件约 20GB,根据网速需要等待。建议在网络稳定时挂后台下载。
拉取完成后测试:
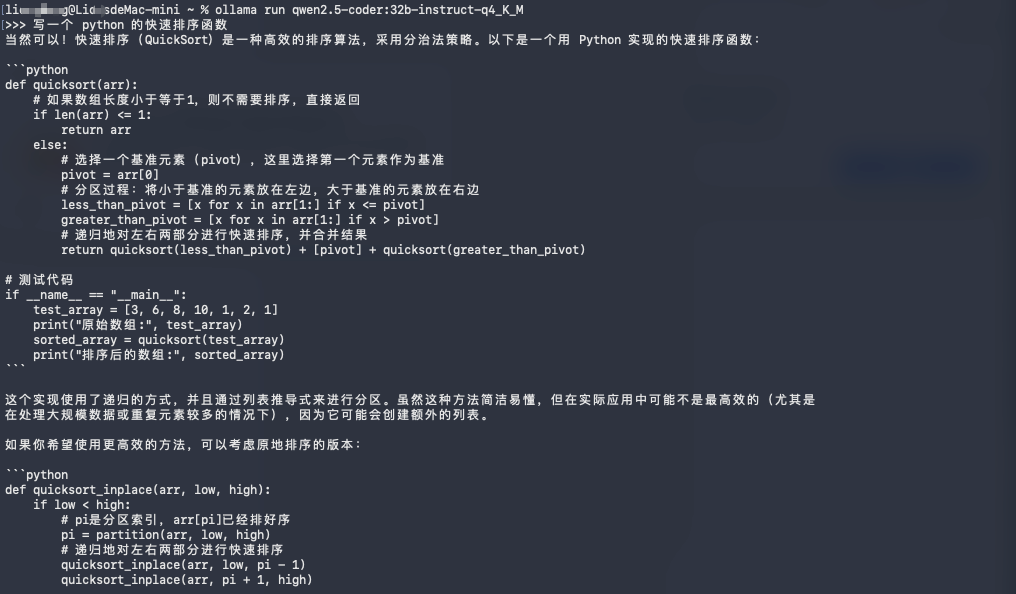
ollama run qwen2.5-coder:32b-instruct-q4_K_M输入 写一个 Python 快速排序函数,确认有正常响应后,输入 /bye 退出。
# 1. 检查 Ollama 是否正在运行
ollama ps
# 2. 直接测试模型是否能响应(排除 Openclaw 问题)
ollama run qwen2.5-coder:32b-instruct-q4_K_M "你现在用的什么模型?"拉取多模态模型
ollama pull qwen2.5vl:7b文件约 5GB。测试:
ollama run qwen2.5vl:7b "描述一下你的能力"确认模型列表
ollama list输出应包含:
NAME ID SIZE MODIFIED
qwen2.5-coder:32b-instruct-q4_K_M ... 20 GB ...
qwen2.5vl:7b ... 5.0 GB ...四、OpenClaw 配置
⚠️ 关键注意事项
不要 使用 Ollama 的 OpenAI 兼容 URL(http://127.0.0.1:11434/v1)接入 OpenClaw。这会破坏工具调用,模型会将原始工具 JSON 作为纯文本输出。
正确的 baseUrl 是:http://127.0.0.1:11434(不加 /v1)
方式一:通过 Onboarding 向导(推荐新手)
openclaw onboard按向导提示依次操作:
- Provider 选择 Ollama
- Base URL 填
http://127.0.0.1:11434(直接回车用默认值) - 模式选择 Local only
- 主模型选
qwen2.5-coder:32b-instruct-q4_K_M
向导会自动写入配置文件。
方式二:手动编辑配置文件(推荐有经验者)
查找配置文件路径:
openclaw config path一般位于 ~/.openclaw/openclaw.json。用编辑器打开,将内容替换为:
{
"models": {
"mode": "merge",
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434",
"apiKey": "ollama-local",
"api": "ollama",
"models": [
{
"id": "qwen2.5-coder:32b-instruct-q4_K_M",
"name": "Qwen2.5 Coder 32B",
"reasoning": false,
"input": ["text"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 131072,
"maxTokens": 8192
},
{
"id": "qwen2.5vl:7b",
"name": "Qwen2.5 VL 7B",
"reasoning": false,
"input": ["text", "image"],
"cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 },
"contextWindow": 32768,
"maxTokens": 4096
}
]
}
}
},
"agents": {
"defaults": {
"model": {
"primary": "ollama/qwen2.5-coder:32b-instruct-q4_K_M",
"fallbacks": ["ollama/qwen2.5vl:7b"]
},
"models": {
"ollama/qwen2.5-coder:32b-instruct-q4_K_M": { "alias": "coder" },
"ollama/qwen2.5vl:7b": { "alias": "vision" }
}
}
}
}保存后重启网关:
openclaw gateway restart验证配置
openclaw models list应能看到两个模型均被识别,provider 标注为 ollama。
五、启动 OpenClaw 并测试
启动网关
openclaw start打开浏览器访问 Web UI:http://localhost:3000
测试一:基础 Coding 能力
发送:
用 Python 写一个读取 CSV 文件并存入 SQLite 数据库的函数,要有完整的异常处理正常情况下应在 30 秒内收到完整、可运行的代码。
测试二:Tool Calling 稳定性
发送:
在当前目录创建一个名为 test.py 的文件,内容是打印 hello world这个任务要求 OpenClaw 调用文件写入工具。完成后检查目录里是否出现了 test.py,验证 tool calling 是否正常。
测试三:多模态图像理解
切换到 vision 模型,发送(并附上一张代码截图):
@vision 分析这张截图里的代码,指出可能存在的 bug测试四:命令行快速测试(无需 UI)
# 直接通过 curl 测试 Ollama API 是否正常
curl http://127.0.0.1:11434/api/chat \
-d '{
"model": "qwen2.5-coder:32b-instruct-q4_K_M",
"messages": [{"role": "user", "content": "用 Python 写 hello world"}],
"stream": false
}'收到正常 JSON 响应即代表 Ollama 服务正常。
测试五:验证 Ollama 服务和模型可用性
# 1. 检查 Ollama 是否正在运行
ollama ps
# 2. 直接测试模型是否能响应(排除 Openclaw 问题)
ollama run qwen2.5-coder:32b-instruct-q4_K_M "你现在用的什么模型?"六、性能优化建议
增大上下文窗口
OpenClaw 的系统 prompt 约 1.7 万 token,加上 KV cache 会额外占用 4-8GB 内存。建议显式设置更大的上下文:
# 启动 Ollama 时设置环境变量
OLLAMA_NUM_CTX=65536 ollama serve或在配置文件里将 contextWindow 设为 65536。
Temperature 设为接近 0
Agent 任务建议将 temperature 设为 0 到 0.2。更高的值容易导致工具调用出现幻觉:
在 openclaw.json 的 agent defaults 里添加:
"temperature": 0.1设置 Ollama 开机自启(launchd)
sudo tee /Library/LaunchDaemons/com.ollama.server.plist << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.ollama.server</string>
<key>ProgramArguments</key>
<array>
<string>/usr/local/bin/ollama</string>
<string>serve</string>
</array>
<key>RunAtLoad</key>
<true/>
<key>KeepAlive</key>
<true/>
<key>EnvironmentVariables</key>
<dict>
<key>OLLAMA_NUM_CTX</key>
<string>65536</string>
</dict>
</dict>
</plist>
EOF
sudo launchctl load /Library/LaunchDaemons/com.ollama.server.plist内存管理建议
- 按需加载模型,不要同时保持两个模型热加载
- 运行 Ollama + 32B 模型时,关闭其他内存占用较大的应用(如 Chrome 多标签页、虚拟机等)
- 量化选 Q4_K_M,不要低于 Q4,否则 tool calling 准确率会明显下降
七、常见问题排查
问题 1:OpenClaw 收不到回复,或只显示原始 JSON
原因: 使用了 /v1 的 OpenAI 兼容 URL。
解决: 确保 baseUrl 是 http://127.0.0.1:11434,删掉 /v1。
openclaw config set models.providers.ollama.baseUrl "http://127.0.0.1:11434"问题 2:模型响应很慢(每个 token 需要几秒)
原因: 正常现象,32B 模型在 M4 Pro 上约 10-20 tok/s。首次请求还需要 10-30 秒将模型从磁盘加载到内存。
解决方向:
- 接受现状:适合后台 agent 任务,不适合实时对话
- 降级到
qwen2.5-coder:14b,速度提升约 2 倍,coding 能力略降 - 确保
OLLAMA_NUM_CTX不要设得过大(超过 128K 会显著拖慢速度)
问题 3:模型没有出现在 OpenClaw 的模型列表
原因: 该模型没有向 Ollama 上报工具支持(tool support)。
解决: 在配置文件的 models.providers.ollama.models 数组里手动定义该模型,并加入 agents.defaults.models 白名单。参见第四节的手动配置示例。
问题 4:内存不足 / 系统卡顿
排查步骤:
# 查看当前内存占用
sudo memory_pressure
# 查看 Ollama 占用
ps aux | grep ollama解决:
- 一次只加载一个大模型
- 减小
OLLAMA_NUM_CTX(从 65536 降到 32768) - 关闭浏览器、IDE 等占内存应用
问题 5:网络下载失败 / 模型拉取中断
# 重新执行 pull,Ollama 支持断点续传
ollama pull qwen2.5-coder:32b-instruct-q4_K_M如果网络不稳定,可考虑从 HuggingFace 手动下载 GGUF 文件后本地导入:
# 手动导入本地 GGUF 文件
ollama create my-coder -f Modelfile八、模型资源链接
| 资源 | 链接 |
|---|---|
| Qwen2.5-Coder 32B(HuggingFace) | https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct |
| Qwen2.5-VL 7B(HuggingFace) | https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct |
| Ollama 模型库 - Qwen2.5-Coder | https://ollama.com/library/qwen2.5-coder |
| Ollama 模型库 - Qwen2.5-VL | https://ollama.com/library/qwen2.5vl |
| OpenClaw 官方文档 | https://docs.openclaw.ai |
| OpenClaw Ollama 集成文档 | https://docs.openclaw.ai/providers/ollama |
| Ollama 官网 | https://ollama.com |
整体架构总结
你(消息渠道 / Web UI)
↓
OpenClaw 网关
↓
Ollama 本地服务(:11434)
↓
qwen2.5-coder:32b / qwen2.5vl:7b
(运行在 Mac mini M4 Pro 48GB 本地)部署完成后完全本地化,零 API 费用,数据不出机器。所有推理在本机 GPU/Neural Engine 上完成,M4 Pro 的 Metal 加速会自动生效。
本文档基于 OpenClaw 2026.x 版本及 Ollama 最新稳定版整理。
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



