
Python:交叉熵-损失函数 (六十)
上一节的答案为什么会是对数呢?因为对数具有良好的特性,即 log(ab)等于 log(a) 和 log(b) 的总和。

我们得到乘积,使用对数,使用底数为 e 的对数(自然对数)而不是底数为 10 的对数,底数为 10 的对数并没有太大的区别,所有原理都是相同的,它只是自然对数的结果乘上一个因子,这样做是一个惯例。
e在科学技术中用得非常多,一般不使用以10为底数的对数。以e为底数,许多式子都能得到简化,用它是最“自然”的,所以叫“自然对数”。
(1+1/n)^n,n越来越大,就越接近它
e是自然对数的底数,是一个无限不循环小数,其值是2.71828……,是这样定义的:
当n->∞时,(1+1/n)^n的极限。
注:x^y表示x的y次方。

我们可以看到,上边的对数都是负数,这是因为 0 到 1 之间的数字的对数都是负值,因为对 1 取对数才能得到 0 ,所以,概率的对数都是负值,对它取相反数是行得通的,这样会得到正数。
这就是我们要做的,我们得到的概率的对数为负值,对它们的相反数进行求和,我们称之为交叉熵(cross entropies),这是本节非常重要的概念。

如果我们计算交叉熵,我们看到左侧错误的模型的交叉熵是 4.8 非常高,右侧的更优的模型的交叉熵较低是 1.2, 实际上这是一个规律,准确的模型可以让我们得到较低的交叉熵,而误差较大的模型得到的交叉熵较高,这纯粹因为好模型可以给我们较高的概率,它的对数取相反数后是个较小的数字,反之亦然。
这种方法比我们想象的还要强大,如果我们计算出概率,并且得到每个点所对应的值,我们实际得到了每个点的误差,可以发现这些分类错误的点的值较大,正确分类的点对应的值都较小,这个还在于正确分类点的概率更接近于1.
因此我们可以把这些对数的相反数作为每个点的误差,分类正确的点较小,分类错误的点较大。
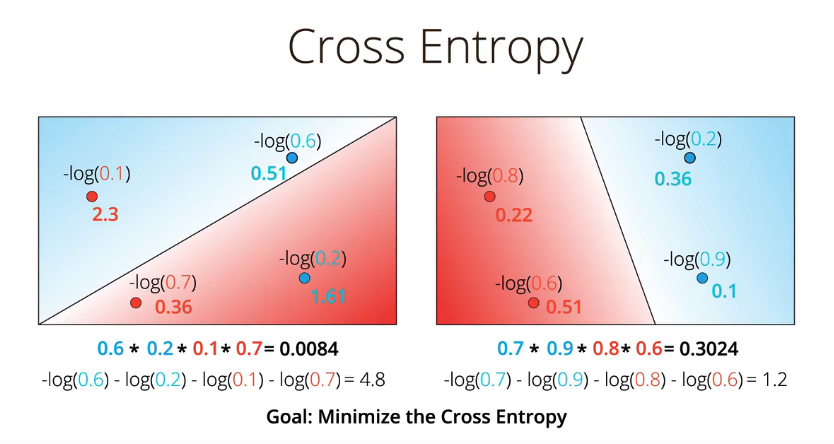
现在我们可以得到结论,交叉熵可以告诉我们模型的好坏。所以,现在我们的目标从最大化概率转变为最小化交叉熵,我们所寻找的误差函数就是这个交叉熵。
交叉熵(cross entropy)
我们遇到了某种规律,概率和误差函数之间肯定有一定的联系,这种联系叫做交叉熵。这个概念在很多领域都非常流行,包括机器学习领域。我们将详细了解该公式,并编写代码!
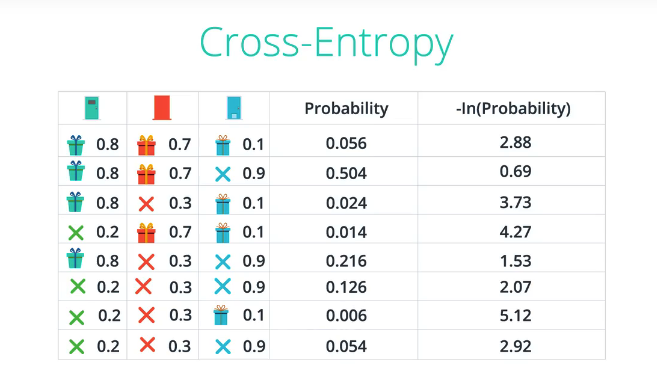
交叉熵公式

CE[(1,1,0),(0.8,0.7,0.1)] = 0.69 说明:(1,1,0)表示概率分布,即是否有礼物
CE[(0,0,1),(0.8,0.7,0.1)] = 5.12
import numpy as np
# Write a function that takes as input two lists Y, P,
# and returns the float corresponding to their cross-entropy.
def cross_entropy(Y, P):
Y = np.float_(Y)
P = np.float_(P)
return -np.sum(Y * np.log(P) + (1 - Y) * np.log(1 - P))
打印:
Trying for Y=[1,0,1,1] and P=[0.4,0.6,0.1,0.5].
The correct answer is
4.8283137373
And your code returned
4.8283137373
Correct!多类别交叉熵
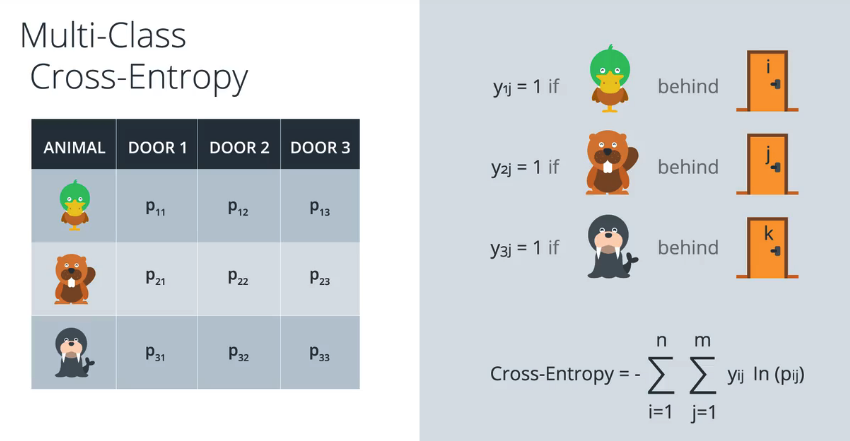
上边我们讨论了两个类别的分类,这次我们讨论两个以上类别的。
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



