
Python3 学习笔记 04-循环、函数、面向对象
循环用于重复执行一些程序块。从上一讲的选择结构,我们已经看到了如何用缩进来表示程序块的隶属关系。循环也会用到类似的写法。
一、循环
1、for循环
for循环需要预先设定好循环的次数(n),然后执行隶属于for的语句n次。
基本构造是:
for 元素 in 序列:
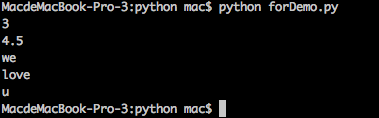
statement举例来说,我们编辑一个叫forDemo.py的文件
for a in [3, 4.5, 'we', 'love', 'u']:
print a这个循环就是每次从表[3,4.4,'life'] 中取出一个元素(回忆:表是一种序列),然后将这个元素赋值给a,之后执行隶属于for的操作(print)。
介绍一个新的Python函数range(),来帮助你建立表。
idx = range(5)
print idx
可以看到idx是[0,1,2,3,4]
这个函数的功能是新建一个表。这个表的元素都是整数,从0开始,下一个元素比前一个大1, 直到函数中所写的上限 (不包括该上限本身)
(关于range(),还有丰富用法,有兴趣可以查阅, Python 3中, range()用法有变化,见评论区)
举例
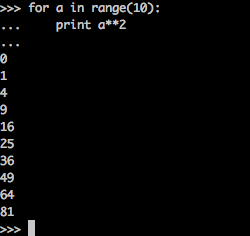
for a in range(10):
print a**2打印结果:
2、while循环
while的用法是:
while 条件:
statementwhile会不停地循环执行隶属于它的语句,直到条件为假(False)
举例
while i < 10:
print i
i = i + 13、中断循环
continue # 在循环的某一次执行中,如果遇到continue, 那么跳过这一次执行,进行下一次的操作
break # 停止执行整个循环
for i in range(10):
if i == 2:
continue
print i当循环执行到i = 2的时候,if条件成立,触发continue, 跳过本次执行(不执行print),继续进行下一次执行(i = 3)。
for i in range(10):
if i == 2:
break
print i当循环执行到i = 2的时候,if条件成立,触发break, 整个循环停止。
二、函数
函数最重要的目的是方便我们重复使用相同的一段程序。
将一些操作隶属于一个函数,以后你想实现相同的操作的时候,只用调用函数名就可以,而不需要重复敲所有的语句。
1、函数的定义
首先,我们要定义一个函数, 以说明这个函数的功能。
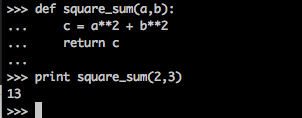
def square_sum(a,b):
c = a**2 + b**2
return c这个函数的功能是求两个数的平方和。
首先,def,这个关键字通知python:我在定义一个函数。square_sum是函数名。
括号中的a, b是函数的参数,是对函数的输入。参数可以有多个,也可以完全没有(但括号要保留)。
我们已经在循环和选择中见过冒号和缩进来表示的隶属关系。
-
c = a2 + b2 # 这一句是函数内部进行的运算
-
return c # 返回c的值,也就是输出的功能。Python的函数允许不返回值,也就是不用return。
-
return可以返回多个值,以逗号分隔。相当于返回一个tuple(定值表)。
-
return a,b,c # 相当于 return (a,b,c) 在python中#代表注释,编译器将跳过#后的内容。
在Python中,当程序执行到return的时候,程序将停止执行函数内余下的语句。return并不是必须的,当没有return, 或者return后面没有返回值时,函数将自动返回None。None是Python中的一个特别的数据类型,用来表示什么都没有,相当于C中的NULL。None多用于关键字参数传递的默认值。
2、函数调用和参数传递
定义过函数后,就可以在后面程序中使用这一函数:
print square_sum(3,4)
Python通过位置,知道3对应的是函数定义中的第一个参数a, 4对应第二个参数b,然后把参数传递给函数square_sum。
(Python有丰富的参数传递方式,还有关键字传递、表传递、字典传递等,基础教程将只涉及位置传递)
函数经过运算,返回值13, 这个13被print打印出来。
我们再看下面两个例子:
a = 1
def change_integer(a):
a = a + 1
return a
print change_integer(a) #注意观察结果
print a #注意观察结果
#===(Python中 "#" 后面跟的内容是注释,不执行 )
b = [1,2,3]
def change_list(b):
b[0] = b[0] + 1
return b
print change_list(b) #注意观察结果
print b #注意观察结果第一个例子,我们将一个整数变量传递给函数,函数对它进行操作,但原整数变量a不发生变化。
第二个例子,我们将一个表传递给函数,函数进行操作,原来的表b发生变化。
对于基本数据类型的变量,变量传递给函数后,函数会在内存中复制一个新的变量,从而不影响原来的变量。(我们称此为值传递)
但是对于表来说,表传递给函数的是一个指针,指针指向序列在内存中的位置,在函数中对表的操作将在原有内存中进行,从而影响原有变量。 (我们称此为指针传递),指针是C/C++语言中的重要概念,有关指针的概念可以到网上搜索相关资料。
三、面向对象的基本概念
Python使用类(class)和对象(object),进行面向对象(object-oriented programming,简称OOP)的编程。
面向对象的最主要目的是提高程序的重复使用性。我们这么早切入面向对象编程的原因是,Python的整个概念是基于对象的。了解OOP是进一步学习Python的关键。
下面是对面向对象的一种理解,基于分类。
1、相近对象,归为类
在人类认知中,会根据属性相近把东西归类,并且给类别命名。比如说,鸟类的共同属性是有羽毛,通过产卵生育后代。任何一只特别的鸟都在鸟类的原型基础上的。
面向对象就是模拟了以上人类认知过程。在Python语言,为了听起来酷,我们把上面说的“东西”称为对象(object)。
先定义鸟类:
class Bird(object):
have_feather = True # 注意:这里的True区分大小写,首字母必须大写,否则报错
way_of_reproduction = 'egg'我们定义了一个类别(class),就是鸟(Bird)。在隶属于这个类比的语句块中,我们定义了两个变量,一个是有羽毛(have_feather),一个是生殖方式(way_of_reproduction),这两个变量对应我们刚才说的属性(attribute)。我们暂时先不说明括号以及其中的内容,记为问题1。
假设我养了一只小鸡,叫summer。它是个对象,且属于鸟类。使用前面定义的类:
summer = Bird()
print summer.way_of_reproduction通过第一句创建对象,并说明summer是类别鸟中的一个对象,summer就有了鸟的类属性,对属性的引用是通过 对象.属性(object.attribute) 的形式实现的。
可怜的summer,你就是个有毛产的蛋货,好不精致。
2、动作
日常认知中,我们在通过属性识别类别的时候,有时根据这个东西能做什么事情来区分类别。比如说,鸟会移动。这样,鸟就和房屋的类别区分开了。这些动作会带来一定的结果,比如移动导致位置的变化。
这样的一些“行为”属性为方法(method)。Python中通过在类的内部定义函数,来说明方法。
class Bird(object):
have_feather = True
way_of_reproduction = 'egg'
def move(self, dx, dy):
position = [0,0]
position[0] = position[0] + dx
position[1] = position[1] + dy
return position
summer = Bird()
print 'after move:',summer.move(5,8)我们重新定义了鸟这个类别。鸟新增一个方法属性,就是表示移动的方法move。(我承认这个方法很傻,你可以在看过下一讲之后定义个有趣些的方法)
(它的参数中有一个self,它是为了方便我们引用对象自身。方法的第一个参数必须是self,无论是否用到。有关self的内容稍后介绍)
另外两个参数,dx, dy表示在x、y两个方向移动的距离。move方法会最终返回运算过的position。
在最后调用move方法的时候,我们只传递了dx和dy两个参数,不需要传递self参数(因为self只是为了内部使用)。
我的summer可以跑了。
3、子类
类别本身还可以进一步细分成子类。
比如说,鸟类可以进一步分成鸡,大雁,黄鹂。
在OOP中,我们通过继承(inheritance)来表达上述概念。
class Chicken(Bird):
way_of_move = 'walk'
possible_in_KFC = True
class Oriole(Bird):
way_of_move = 'fly'
possible_in_KFC = False
summer = Chicken()
print summer.have_feather
print summer.move(5,8)新定义的鸡(Chicken)类的,增加了两个属性:移动方式(way_of_move),可能在KFC找到(possible_in_KFC)。
在类定义时,括号里为了Bird。这说明,Chicken是属于鸟类(Bird)的一个子类,即Chicken继承自Bird。自然而然,Bird就是Chicken的父类。Chicken将享有Bird的所有属性。尽管我只声明了summer是鸡类,它通过继承享有了父类的属性(无论是变量属性have_feather还是方法属性move)
新定义的黄鹂(Oriole)类,同样继承自鸟类。在创建一个黄鹂对象时,该对象自动拥有鸟类的属性。
通过继承制度,我们可以减少程序中的重复信息和重复语句。如果我们分别定义两个类,而不继承自鸟类,就必须把鸟类的属性分别输入到鸡类和黄鹂类的定义中。整个过程会变得繁琐,因此,面向对象提高了程序的可重复使用性。
(回到问题1, 括号中的object,当括号中为object时,说明这个类没有父类(到头了))
将各种各样的东西分类,从而了解世界,从人类祖先开始,我们就在练习了这个认知过程,面向对象是符合人类思维习惯的。所谓面向过程,也就是执行完一个语句再执行下一个,更多的是机器思维。通过面向对象的编程,我们可以更方便的表达思维中的复杂想法。
四、面向对象的进一步拓展
1、调用类的其它信息
刚才提到,在定义方法时,必须有self这一参数。这个参数表示某个对象。对象拥有类的所有性质(如果学习过Java 或C++等语言的便会知道,self相当于this),那么我们可以通过self,调用类属性。
class Human(object):
laugh = 'hahahaha'
def show_laugh(self):
print self.laugh
def laugh_100th(self):
for i in range(100):
self.show_laugh()
li_lei = Human()
li_lei.laugh_100th()这里有一个类属性laugh。在方法show_laugh()中,通过self.laugh,调用了该属性的值。
还可以用相同的方式调用其它方法。方法show_laugh(),在方法laugh_100th中()被调用。
在对象中对类属性进行赋值的时候,实际上会在对象定义的作用域中添加一个属性(如果还不存在的话),并不会影响到相应类中定义的同名类属性。但如果是修改类属性的内容(比如类属性是个字典,修改字典内容)时会影响到所有对象实例,因为这个类属性的内容是共享的。
2、init() 方法
init() 是一个特殊方法(special method)。Python有一些特殊方法。Python会特殊的对待它们。特殊方法的特点是名字前后有两个下划线。
如果你在类中定义了init() 这个方法,创建对象时,Python会自动调用这个方法。这个过程也叫初始化。
class happyBird(Bird):
def init(self,more_words):
print 'We are happy birds.',more_words
summer = happyBird('Happy,Happy!')
这里继承了Bird类。屏幕上打印:
We are happy birds.Happy,Happy!
我们看到,尽管我们只是创建了summer对象,但init() 方法被自动调用了。最后一行的语句(summer = happyBird...)先创建了对象,然后执行:
summer.__init__(more_words)'Happy,Happy!' 被传递给了init() 的参数more_words
3、对象的性质
我们讲到了许多属性,但这些属性是类的属性。所有属于该类的对象会共享这些属性。比如说,鸟都有羽毛,鸡都不会飞。
在一些情况下,我们定义对象的性质,用于记录该对象的特别信息。比如说,人这个类。性别是某个人的一个性质,不是所有的人类都是男,或者都是女。这个性质的值随着对象的不同而不同。李雷是人类的一个对象,性别是男;韩美美也是人类的一个对象,性别是女。
当定义类的方法时,必须要传递一个self的参数。这个参数指代的就是类的一个对象。我们可以通过操纵self,来修改某个对象的性质。比如用类来新建一个对象,即下面例子中的li_lei, 那么li_lei就被self表示。我们通过赋值给self.attribute,给li_lei这一对象增加一些性质,比如说性别的男女。self会传递给各个方法。在方法内部,可以通过引用self.attribute,查询或修改对象的性质。
这样,在类属性的之外,又给每个对象增添了各自特色的性质,从而能描述多样的世界。
class Human(object):
def __init__(self, input_gender):
self.gender = input_gender
def printGender(self):
print self.gender
li_lei = Human('male') # 这里,'male'作为参数传递给__init__()方法的input_gender变量。
print li_lei.gender #这一行结果与下一行对比
li_lei.printGender() #这一行结果与上一行对比在初始化中,将参数input_gender,赋值给对象的性质,即self.gender。
li_lei拥有了对象性质gender。gender不是一个类属性。Python在建立了li_lei这一对象之后,使用li_lei.gender这一对象性质,专门储存属于对象li_lei的特有信息。
对象的性质也可以被其它方法调用,调用方法与类属性的调用相似,正如在printGender()方法中的调用。
结果打印:
五、反过头来看看
从最初的“Hello World”,走到面向对象。该回过头来看看,教程中是否遗漏了什么。
我们之前提到一句话,"Everything is Object". 那么我们就深入体验一下这句话。
需要先要介绍两个内置函数:dir() 和 help() 。
dir()用来查询一个类或者对象所有属性。你可以尝试一下:
>>>print dir(list)help()用来查询的说明文档。你可以尝试一下:
>>>print help(list)(list是Python内置的一个类,对应于我们之前讲解过的列表)
1、list是一个类
在上面以及看到,表是Python已经定义好的一个类。当我们新建一个表时,比如:
>>>nl = [1,2,5,3,5]实际上,nl是类list的一个对象。
实验一些list的方法:
>>>print nl.count(5) # 计数,看总共有多少个5
>>>print nl.index(3) # 查询 nl 的第一个3的下标
>>>nl.append(6) # 在 nl 的最后增添一个新元素6
>>>nl.sort() # 对nl的元素排序
>>>print nl.pop() # 从nl中去除最后一个元素,并将该元素返回。
>>>nl.remove(2) # 从nl中去除第一个2
>>>nl.insert(0,9) # 在下标为0的位置插入9总之,list是一个类。每个列表都属于该类。
Python补充中有list常用方法的附录。
2、运算符是特殊方法
使用dir(list)的时候,能看到一个属性,是add()。从形式上看是特殊方法(下划线,下划线)。它特殊在哪呢?
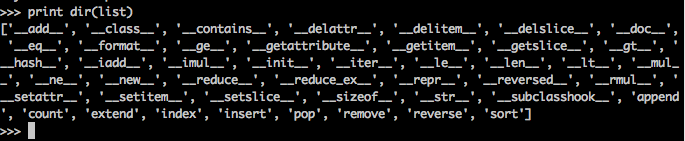
这个方法定义了"+"运算符对于list对象的意义,两个list的对象相加时,会进行的操作。
>>>print [1,2,3] + [5,6,9]
[1, 2, 3, 5, 6, 9]运算符,比如+, -, >, <, 以及下标引用[start:end]等等,从根本上都是定义在类内部的方法。
尝试一下:
>>>print [1,2,3] - [3,4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for -: 'list' and 'list'会有错误信息,说明该运算符“-”没有定义。现在我们继承list类,添加对"-"的定义:
class superList(list):
def __sub__(self, b):
a = self[:] # 这里,self是supeList的对象。由于superList继承于list,它可以利用和list[:]相同的引用方法来表示整个对象。
b = b[:]
while len(b) > 0:
element_b = b.pop()
if element_b in a:
a.remove(element_b)
return aprint superList([1,2,3]) - superList([3,4])
内置函数len()用来返回list所包含的元素的总数。内置函数sub() 定义了“-”的操作:从第一个表中去掉第二个表中出现的元素。如果sub() 已经在父类中定义,你又在子类中定义了,那么子类的对象会参考子类的定义,而不会载入父类的定义。任何其他的属性也是这样。
(教程最后也会给出一个特殊方法的清单)
定义运算符对于复杂的对象非常有用。举例来说,人类有多个属性,比如姓名,年龄和身高。我们可以把人类的比较(>, <, =)定义成只看年龄。这样就可以根据自己的目的,将原本不存在的运算增加在对象上了。
3、下一步
希望你已经对Python有了一个基本了解。你可能跃跃欲试,要写一些程序练习一下。这会对你很有好处。
但是,Python的强大很大一部分原因在于,它提供有很多已经写好的,可以现成用的对象。我们已经看到了内置的比如说list,还有tuple等等。它们用起来很方便。在Python的标准库里,还有大量可以用于操作系统互动,Internet开发,多线程,文本处理的对象。而在所有的这些的这些的基础上,又有很多外部的库包,定义了更丰富的对象,比如numpy, tkinter, django等用于科学计算,GUI开发,web开发的库,定义了各种各样的对象。对于一般用户来说,使用这些库,要比自己去从头开始容易得多。我们要开始攀登巨人的肩膀了。
谢谢你的关注,
欢迎来到Python的世界。
为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)


