
自动驾驶-nuScenes 数据探索
现在让我们动手操作 nuScenes 数据集,看看真实数据长什么样。
nuScenes 数据集深度实操
环境配置:
conda create -n python311 python=3.11 -y
conda activate python311
pip install NuScenes
pip install nuscenes-devkit
# 查看环境
conda env list
gptCode /Users/kaiyi/.conda/envs/gptCode
hivestudy /Users/kaiyi/.conda/envs/hivestudy
mrmp_running /Users/kaiyi/.conda/envs/mrmp_running
pythonStudy /Users/kaiyi/.conda/envs/pythonStudy
ymir /Users/kaiyi/.conda/envs/ymir
base /Users/kaiyi/miniconda3
ai-crypto-officer /Users/kaiyi/miniconda3/envs/ai-crypto-officer
d2l /Users/kaiyi/miniconda3/envs/d2l
llm /Users/kaiyi/miniconda3/envs/llm
py311 /Users/kaiyi/miniconda3/envs/py311
python311 * /Users/kaiyi/miniconda3/envs/python311
trading-env /Users/kaiyi/miniconda3/envs/trading-env
tradingbit /Users/kaiyi/miniconda3/envs/tradingbit
/Users/kaiyi/opt/anaconda3
nuScenes_test.py 脚本
# nuScenes 数据探索脚本
from nuscenes.nuscenes import NuScenes
from nuscenes.utils.data_classes import LidarPointCloud
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
nusc = NuScenes(version='v1.0-mini',
dataroot='./data/nuscenes/v1.0-mini',
verbose=True)
# 查看第一个场景的第一个样本
sample = nusc.sample[0]
# 获取 6 个摄像头的图像
cam_names = ['CAM_FRONT_LEFT', 'CAM_FRONT', 'CAM_FRONT_RIGHT',
'CAM_BACK_LEFT', 'CAM_BACK', 'CAM_BACK_RIGHT']
fig, axes = plt.subplots(2, 3, figsize=(18, 8))
for i, cam in enumerate(cam_names):
cam_data = nusc.get('sample_data', sample['data'][cam])
img = Image.open(f"./data/nuscenes/v1.0-mini/{cam_data['filename']}")
axes[i//3, i%3].imshow(img)
axes[i//3, i%3].set_title(cam, fontsize=12)
axes[i//3, i%3].axis('off')
plt.tight_layout()
plt.savefig('6_cameras.png', dpi=150)
print('✅ 6 个摄像头图像已保存')
# 查看相机内外参数(BEVFormer 用它来做 3D→2D 投影)
cam_token = sample['data']['CAM_FRONT']
cam_data = nusc.get('sample_data', cam_token)
calibrated = nusc.get('calibrated_sensor',
cam_data['calibrated_sensor_token'])
print(f"相机内参 (3x3):")
print(np.array(calibrated['camera_intrinsic']))
print(f"\n相机外参 (平移): {calibrated['translation']}")
print(f"相机外参 (旋转): {calibrated['rotation']}")
# 这些参数就是 BEVFormer 做空间交叉注意力时
# 把 3D 参考点投影到 2D 图像上的关键输入
# 查看 3D 框标注
for ann_token in sample['anns'][:5]:
ann = nusc.get('sample_annotation', ann_token)
print(f"类别: {ann['category_name']:<30} "
f"位置: ({ann['translation'][0]:.1f}, "
f"{ann['translation'][1]:.1f}, "
f"{ann['translation'][2]:.1f}) "
f"尺寸: {ann['size']}")进行 debug 调试,下边为打印日志:
(python311) ➜ autoLab cd /Users/kaiyi/Work/AI/autoLab ; /usr/bin/env /Users/kaiyi/miniconda3/envs/python31
1/bin/python /Users/kaiyi/.vscode/extensions/ms-python.debugpy-2025.18.0-darwin-x64/bundled/libs/debugpy/ada
pter/../../debugpy/launcher 56136 -- /Users/kaiyi/Work/AI/autoLab/nuScenes_test.py
Backend macosx is interactive backend. Turning interactive mode on.
======
Loading NuScenes tables for version v1.0-mini...
23 category,
8 attribute,
4 visibility,
911 instance,
12 sensor,
120 calibrated_sensor,
31206 ego_pose,
8 log,
10 scene,
404 sample,
31206 sample_data,
18538 sample_annotation,
4 map,
Done loading in 0.521 seconds.
======
Reverse indexing ...
Done reverse indexing in 0.3 seconds.
======
✅ 6 个摄像头图像已保存
相机内参 (3x3):
[[1.26641720e+03 0.00000000e+00 8.16267020e+02]
[0.00000000e+00 1.26641720e+03 4.91507066e+02]
[0.00000000e+00 0.00000000e+00 1.00000000e+00]]
相机外参 (平移): [1.70079118954, 0.0159456324149, 1.51095763913]
相机外参 (旋转): [0.4998015430569128, -0.5030316162024876, 0.4997798114386805, -0.49737083824542755]
类别: human.pedestrian.adult 位置: (373.3, 1130.4, 0.8) 尺寸: [0.621, 0.669, 1.642]
类别: human.pedestrian.adult 位置: (378.9, 1153.3, 0.9) 尺寸: [0.775, 0.769, 1.711]
类别: vehicle.car 位置: (353.8, 1132.4, 0.6) 尺寸: [2.011, 4.633, 1.573]
类别: human.pedestrian.adult 位置: (376.1, 1158.5, 0.9) 尺寸: [0.752, 0.819, 1.637]
类别: movable_object.trafficcone 位置: (410.1, 1196.8, 0.7) 尺寸: [0.427, 0.359, 0.794]
(python311) ➜ autoLab 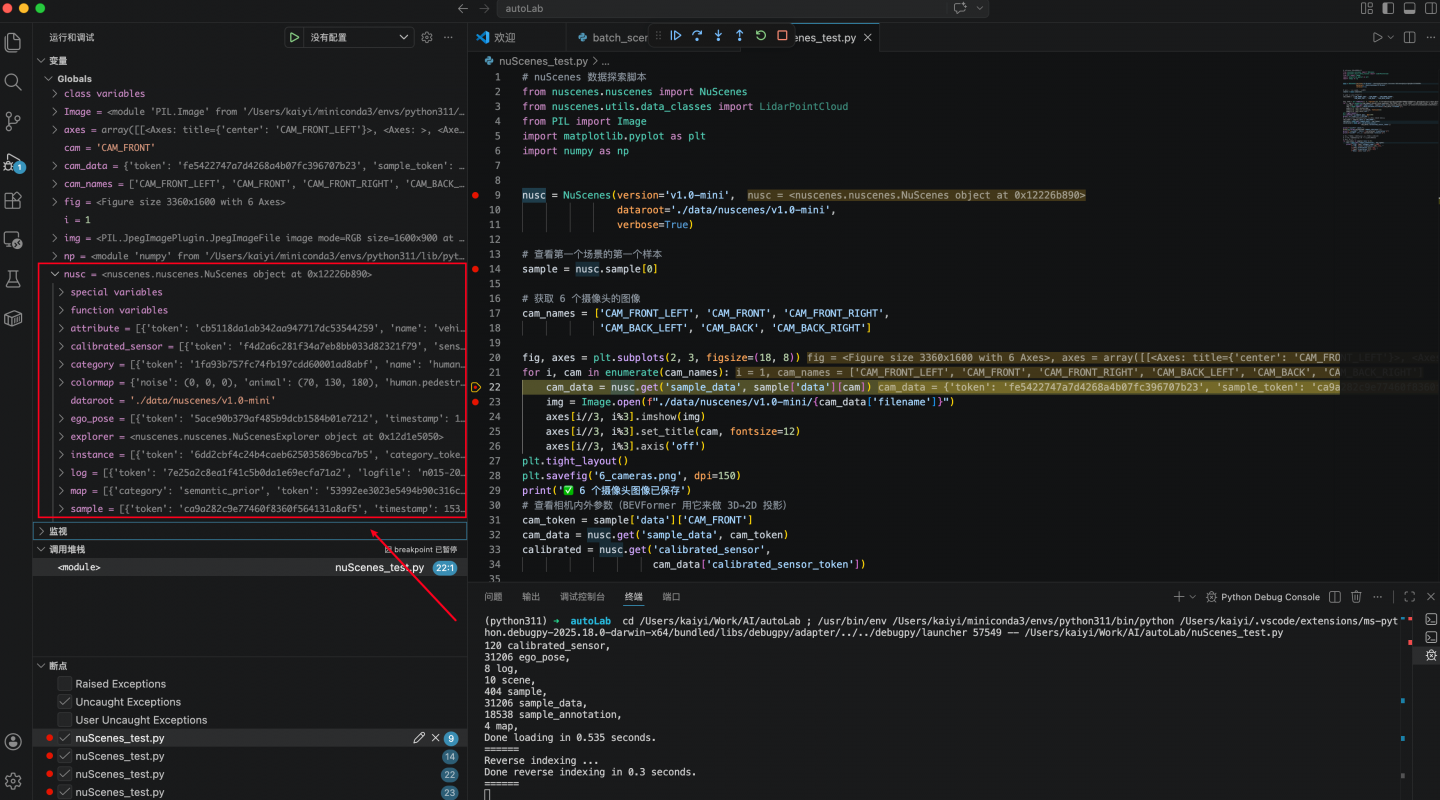

基于Qwen2.5-VL的MiniVLA轨迹预测训练
- 补全 NuScenes 数据集加载 + Dataloader
- 修复模型前向传播的批量处理问题
- 适配真实自动驾驶场景数据格式
- 保证代码可直接运行训练
依赖环境:
(carla) lionsking@ai-dev:~/data/nuscenes$ pwd
/home/lionsking/data/nuscenes
(carla) lionsking@ai-dev:~/data/nuscenes$ ls -l
total 4833592
drwxrwxr-x 2 lionsking lionsking 413696 Jan 24 2020 can_bus
-rw-rw-r-- 1 lionsking lionsking 780974697 May 5 17:33 can_bus.zip
-rw-r--r-- 1 lionsking lionsking 25319 Jan 31 2024 LICENSE
drwxr-xr-x 2 lionsking lionsking 4096 Mar 23 2019 maps
drwxrwxr-x 14 lionsking lionsking 4096 Mar 18 2019 samples
drwxrwxr-x 14 lionsking lionsking 4096 Mar 18 2019 sweeps
drwxr-xr-x 2 lionsking lionsking 4096 Mar 23 2019 v1.0-mini
-rw-rw-r-- 1 lionsking lionsking 4168148189 May 5 17:33 v1.0-mini.tgz
下载依赖:
# 核心依赖
# NuScenes 工具包
pip install nuscenes-devkit import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from nuscenes import NuScenes
from nuscenes.utils.data_classes import LidarPointCloud, Box
from nuscenes.utils.geometry_utils import transform_matrix
from pyquaternion import Quaternion
import os
import numpy as np
from PIL import Image
from tqdm import tqdm
# ===================== 1. 修复:NuScenes 数据集定义 =====================
class NuScenesTrajDataset(Dataset):
"""
NuScenes 数据集:加载相机图像 + 驾驶指令 + 自车速度 + 真实轨迹
简化版:取前视相机图像,预测未来6个轨迹点 (x,y)
"""
def __init__(self, nusc_root, nusc_version='v1.0-mini', seq_len=6):
self.nusc = NuScenes(version=nusc_version, dataroot=nusc_root, verbose=True)
self.seq_len = seq_len # 预测6个轨迹点
self.sample_tokens = [s['token'] for s in self.nusc.sample]
def __len__(self):
return len(self.sample_tokens)
def __getitem__(self, idx):
"""加载单帧数据:图像、指令、速度、真实轨迹"""
sample = self.nusc.get('sample', self.sample_tokens[idx])
# ========== 1. 加载前视相机图像 ==========
cam_data = self.nusc.get('sample_data', sample['data']['CAM_FRONT'])
cam_path = os.path.join(self.nusc.dataroot, cam_data['filename'])
image = Image.open(cam_path).convert('RGB')
# ========== 2. 生成驾驶指令(简化:直行/左转/右转) ==========
ego_pose = self.nusc.get('ego_pose', cam_data['ego_pose_token'])
yaw = Quaternion(ego_pose['rotation']).yaw_pitch_roll[0]
if -0.3 < yaw < 0.3:
command = "drive straight"
elif yaw >= 0.3:
command = "turn left"
else:
command = "turn right"
# ========== 3. 自车速度(简化:固定/从数据集读取) ==========
speed = 5.0 # m/s
# ========== 4. 加载未来真实轨迹 (x,y) 6个点 ==========
traj = np.zeros((self.seq_len, 2), dtype=np.float32)
current_token = self.sample_tokens[idx]
for i in range(self.seq_len):
if current_token in self.nusc.sample:
next_sample = self.nusc.get('sample', current_token)
next_cam = self.nusc.get('sample_data', next_sample['data']['CAM_FRONT'])
next_pose = self.nusc.get('ego_pose', next_cam['ego_pose_token'])
traj[i] = [next_pose['translation'][0], next_pose['translation'][1]]
current_token = next_sample.get('next', '')
# 轨迹归一化(相对于当前自车位置)
current_trans = np.array(ego_pose['translation'][:2])
traj = traj - current_trans[None, :]
return image, command, np.float32(speed), torch.from_numpy(traj)
# ===================== 2. 修复:模型批量处理 + 训练适配 =====================
class MiniVLA(nn.Module):
def __init__(self, vlm_name='Qwen/Qwen2.5-VL-3B-Instruct',
num_waypoints=6, freeze_vlm=True):
super().__init__()
# 加载预训练 VLM
self.vlm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
vlm_name, torch_dtype=torch.float16)
self.processor = AutoProcessor.from_pretrained(vlm_name)
# 冻结 VLM 参数
if freeze_vlm:
for p in self.vlm.parameters():
p.requires_grad = False
# 轨迹预测头
hidden = self.vlm.config.hidden_size
self.traj_head = nn.Sequential(
nn.Linear(hidden, 512), nn.ReLU(), nn.Dropout(0.1),
nn.Linear(512, 256), nn.ReLU(),
nn.Linear(256, num_waypoints * 2)
)
def forward(self, images, driving_commands, ego_speeds):
"""批量处理修复:支持多张图像+多个指令"""
# 构建批量 prompt
prompts = [f'Command: {cmd}. Speed: {sp:.1f}m/s.'
for cmd, sp in zip(driving_commands, ego_speeds)]
# 批量预处理
inputs = self.processor(
text=prompts,
images=images,
return_tensors='pt',
padding=True
).to(self.vlm.device)
# 提取 VLM 特征
with torch.no_grad():
out = self.vlm(**inputs, output_hidden_states=True)
# 取最后一层最后一个 token 特征
h = out.hidden_states[-1][:, -1, :].float()
traj = self.traj_head(h)
return traj.view(-1, 6, 2) # (B, 6, 2)
# ===================== 3. 修复:完整训练流程(含 Dataloader) =====================
def train():
# ========== 配置参数 ==========
NUSCENES_ROOT = "/data/nuscenes" # 你自己的 NuScenes 数据集路径
BATCH_SIZE = 2
EPOCHS = 20
LR = 1e-3
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# ========== 加载数据集 ==========
dataset = NuScenesTrajDataset(nusc_root=NUSCENES_ROOT)
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
pin_memory=True
)
# ========== 模型、优化器、损失 ==========
model = MiniVLA(freeze_vlm=True).to(DEVICE)
optimizer = torch.optim.Adam(model.traj_head.parameters(), lr=LR)
loss_fn = nn.SmoothL1Loss()
# ========== 训练循环 ==========
print("开始训练...")
model.train()
for epoch in range(EPOCHS):
total_loss = 0.0
pbar = tqdm(dataloader, desc=f"Epoch {epoch+1}/{EPOCHS}")
for images, commands, speeds, gt_traj in pbar:
# 数据搬到 GPU
gt_traj = gt_traj.to(DEVICE)
# 前向 + 损失
pred_traj = model(images, commands, speeds)
loss = loss_fn(pred_traj, gt_traj)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix(loss=loss.item())
avg_loss = total_loss / len(dataloader)
print(f"Epoch {epoch+1} 平均损失: {avg_loss:.4f}")
# 保存训练好的轨迹头
torch.save(model.traj_head.state_dict(), 'vla_traj_head.pth')
print("训练完成,模型已保存为 vla_traj_head.pth")
if __name__ == "__main__":
train()
VLA 训练
mini_vla_nusce.py
import os
# ===================== 【国内核心设置】全局切换为国内镜像 Qwen2.5-VL=====================
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # huggingface 国内镜像
os.environ["TRANSFORMERS_OFFLINE"] = "0"
os.environ['HUGGINGFACE_HUB_CACHE'] = './model_cache'
os.environ['TRANSFORMERS_CACHE'] = './model_cache'
os.environ['HF_HUB_DOWNLOAD_TIMEOUT'] = '600'
# ================ 之后才能 import 其他库 ================
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from nuscenes import NuScenes
from nuscenes.utils.data_classes import LidarPointCloud, Box
from nuscenes.utils.geometry_utils import transform_matrix
from pyquaternion import Quaternion
import numpy as np
from PIL import Image
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
# ===================== 1. 修复:NuScenes 数据集定义 =====================
class NuScenesTrajDataset(Dataset):
"""
NuScenes 数据集:加载相机图像 + 驾驶指令 + 自车速度 + 真实轨迹
简化版:取前视相机图像,预测未来6个轨迹点 (x,y)
#【核心改动】只加载前 N 条数据的小数据集
"""
def __init__(self, nusc_root, nusc_version='v1.0-mini', seq_len=6, max_samples=100):
self.nusc = NuScenes(version=nusc_version, dataroot=nusc_root, verbose=True)
self.seq_len = seq_len # 预测6个轨迹点
self.sample_tokens = [s['token'] for s in self.nusc.sample]
# ================ ✅ 关键:只取前 N 个样本 ================
self.sample_tokens = self.sample_tokens[:max_samples]
print(f"✅ 只加载数据集前 {max_samples} 条!")
def __len__(self):
return len(self.sample_tokens)
def __getitem__(self, idx):
"""加载单帧数据:图像、指令、速度、真实轨迹"""
sample = self.nusc.get('sample', self.sample_tokens[idx])
# ========== 1. 加载前视相机图像 ==========
cam_data = self.nusc.get('sample_data', sample['data']['CAM_FRONT'])
cam_path = os.path.join(self.nusc.dataroot, cam_data['filename'])
image = Image.open(cam_path).convert('RGB')
# ========== 2. 生成驾驶指令(简化:直行/左转/右转) ==========
ego_pose = self.nusc.get('ego_pose', cam_data['ego_pose_token'])
yaw = Quaternion(ego_pose['rotation']).yaw_pitch_roll[0]
if -0.3 < yaw < 0.3:
command = "drive straight"
elif yaw >= 0.3:
command = "turn left"
else:
command = "turn right"
# ========== 3. 自车速度(简化:固定/从数据集读取) ==========
speed = 5.0 # m/s
# ========== 4. 加载未来真实轨迹 (x,y) 6个点 ==========
traj = np.zeros((self.seq_len, 2), dtype=np.float32)
current_token = self.sample_tokens[idx]
for i in range(self.seq_len):
if current_token in self.nusc.sample:
next_sample = self.nusc.get('sample', current_token)
next_cam = self.nusc.get('sample_data', next_sample['data']['CAM_FRONT'])
next_pose = self.nusc.get('ego_pose', next_cam['ego_pose_token'])
traj[i] = [next_pose['translation'][0], next_pose['translation'][1]]
current_token = next_sample.get('next', '')
# 轨迹归一化(相对于当前自车位置)
current_trans = np.array(ego_pose['translation'][:2])
traj = traj - current_trans[None, :]
return image, command, np.float32(speed), torch.from_numpy(traj)
# ===================== 2. 修复:模型批量处理 + 训练适配 =====================
class MiniVLA(nn.Module):
def __init__(self, vlm_name='Qwen/Qwen2.5-VL-3B-Instruct',
num_waypoints=6, freeze_vlm=True):
super().__init__()
print("✅ 从国内镜像加载模型...")
# 加载预训练 VLM
self.vlm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
vlm_name,
torch_dtype=torch.float16,
trust_remote_code=True)
self.processor = AutoProcessor.from_pretrained(vlm_name,
trust_remote_code=True)
# 冻结 VLM 参数
if freeze_vlm:
for p in self.vlm.parameters():
p.requires_grad = False
# 轨迹预测头
# hidden = self.vlm.config.hidden_sizes
# hidden = self.vlm.config.hidden_sizes[-1]
# ===================== ✅ 终极修复:Qwen2.5-VL 正确维度 =====================
# 3B 模型 = 2048,7B 模型 = 3584,直接写死最稳定
# hidden = 2048 # Qwen2.5-VL-3B 固定维度
hidden = 3584 # 如果用 7B 模型就打开这个
self.traj_head = nn.Sequential(
nn.Linear(hidden, 512), nn.ReLU(), nn.Dropout(0.1),
nn.Linear(512, 256), nn.ReLU(),
nn.Linear(256, num_waypoints * 2)
)
def forward(self, images, driving_commands, ego_speeds):
"""批量处理修复:支持多张图像+多个指令"""
# 构建批量 prompt
prompts = [f'Command: {cmd}. Speed: {sp:.1f}m/s.'
for cmd, sp in zip(driving_commands, ego_speeds)]
# 批量预处理
inputs = self.processor(
text=prompts,
images=images,
return_tensors='pt',
padding=True
).to(self.vlm.device)
# 提取 VLM 特征
with torch.no_grad():
out = self.vlm(**inputs, output_hidden_states=True)
# 取最后一层最后一个 token 特征
h = out.hidden_states[-1][:, -1, :].float()
traj = self.traj_head(h)
return traj.view(-1, 6, 2) # (B, 6, 2)
# ===================== 3. 修复:完整训练流程(含 Dataloader) =====================
def train():
# ========== 配置参数 ==========
NUSCENES_ROOT = "/home/lionsking/data/nuscenes" # 你自己的 NuScenes 数据集路径
BATCH_SIZE = 1
EPOCHS = 20
LR = 1e-3
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# ========== 加载数据集 ==========
dataset = NuScenesTrajDataset(nusc_root=NUSCENES_ROOT)
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
pin_memory=True
)
# ========== 模型、优化器、损失 ==========
model = MiniVLA(freeze_vlm=True).to(DEVICE)
optimizer = torch.optim.Adam(model.traj_head.parameters(), lr=LR)
loss_fn = nn.SmoothL1Loss()
# ========== 训练循环 ==========
print("开始训练...")
model.train()
for epoch in range(EPOCHS):
total_loss = 0.0
pbar = tqdm(dataloader, desc=f"Epoch {epoch+1}/{EPOCHS}")
for images, commands, speeds, gt_traj in pbar:
# 数据搬到 GPU
gt_traj = gt_traj.to(DEVICE)
# 前向 + 损失
pred_traj = model(images, commands, speeds)
loss = loss_fn(pred_traj, gt_traj)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix(loss=loss.item())
avg_loss = total_loss / len(dataloader)
print(f"Epoch {epoch+1} 平均损失: {avg_loss:.4f}")
# 保存训练好的轨迹头
torch.save(model.traj_head.state_dict(), 'vla_traj_head.pth')
print("训练完成,模型已保存为 vla_traj_head.pth")
if __name__ == "__main__":
train()
执行结果:
(carla) lionsking@ai-dev:~/Code/auto_self$ python mini_vla_nusce.py
======
Loading NuScenes tables for version v1.0-mini...
23 category,
8 attribute,
4 visibility,
911 instance,
12 sensor,
120 calibrated_sensor,
31206 ego_pose,
8 log,
10 scene,
404 sample,
31206 sample_data,
18538 sample_annotation,
4 map,
Done loading in 0.242 seconds.
======
Reverse indexing ...
Done reverse indexing in 0.0 seconds.
======
✅ 只加载数据集前 100 条!
✅ 从国内镜像加载模型...
Fetching 5 files: 100%|██████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 13214.57it/s]
Download complete: : 0.00B [00:00, ?B/s] | 0/5 [00:00<?, ?it/s]
Loading weights: 100%|█████████████████████████████████████████████████████████████████████████████| 729/729 [00:03<00:00, 196.37it/s]
Traceback (most recent call last):
File "/home/lionsking/Code/auto_self/mini_vla_nusce.py", line 197, in <module>
train()
File "/home/lionsking/Code/auto_self/mini_vla_nusce.py", line 162, in train
model = MiniVLA(freeze_vlm=True).to(DEVICE)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1384, in to
return self._apply(convert)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/nn/modules/module.py", line 934, in _apply
module._apply(fn)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/nn/modules/module.py", line 934, in _apply
module._apply(fn)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/nn/modules/module.py", line 934, in _apply
module._apply(fn)
[Previous line repeated 4 more times]
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/nn/modules/module.py", line 965, in _apply
param_applied = fn(param)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1370, in convert
return t.to(
torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 130.00 MiB. GPU 0 has a total capacity of 7.53 GiB of which 127.50 MiB is free. Including non-PyTorch memory, this process has 7.35 GiB memory in use. Of the allocated memory 7.13 GiB is allocated by PyTorch, and 122.86 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://docs.pytorch.org/docs/stable/notes/cuda.html#optimizing-memory-usage-with-pytorch-cuda-alloc-conf)
(carla) lionsking@ai-dev:~/Code/auto_self$ nvidia-smi
Sun May 10 12:17:35 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 5060 ... Off | 00000000:01:00.0 Off | N/A |
| N/A 44C P8 3W / 70W | 47MiB / 8151MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 72953 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+
(carla) lionsking@ai-dev:~/Code/auto_self$
Kaiyi,问题很清楚:Qwen2.5-VL-3B 模型在 fp16 下大约需要 ~7GB 显存,加上 traj_head 和 PyTorch 本身的开销,8GB 的 RTX 5060 装不下。
你的代码里还有一个隐藏问题:hidden = 3584 是 7B 的维度,但你实际加载的是 3B 模型(Qwen2.5-VL-3B-Instruct),3B 的 hidden size 是 2048。这会导致维度不匹配的 runtime error(即使显存够也会报错)。
下面是修复方案,按优先级排列:
方案一:混合精度 + CPU offload(改动最小)
把 VLM 留在 CPU,只把 traj_head 放 GPU,前向推理时用 CPU 跑 VLM:
# train() 函数中,替换模型加载部分:
model = MiniVLA(freeze_vlm=True)
model.vlm = model.vlm.to("cpu") # VLM 留 CPU
model.traj_head = model.traj_head.to(DEVICE) # 只有轨迹头上 GPU
# forward() 中对应修改 —— h 提取后再搬到 GPU:
h = out.hidden_states[-1][:, -1, :].float().to(self.traj_head[0].weight.device)这样 GPU 只占几十 MB,但训练速度会慢很多(VLM 在 CPU 上推理)。
方案二:换更小的 VLM(推荐)
8GB 显存跑 3B VLM 本身就很勉强。建议换成更小的模型:
# 选项 A:Qwen2.5-VL-2B(如果有的话)
vlm_name = 'Qwen/Qwen2.5-VL-2B-Instruct'
# 选项 B:用 CLIP 作为视觉编码器,更轻量
# 这也更符合你书中 Chapter 9 VLA 的教学定位方案三:4-bit 量化加载(最实用)
from transformers import BitsAndBytesConfig
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4"
)
self.vlm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
vlm_name,
quantization_config=quantization_config,
device_map="auto", # 自动分配 GPU/CPU
trust_remote_code=True
)需要安装 pip install bitsandbytes。4-bit 量化后 3B 模型大约只占 ~2GB 显存,剩余空间足够跑训练。
另外必须修复的 bug:
# hidden 维度写错了,3B 模型应该是 2048,不是 3584
hidden = 2048 # Qwen2.5-VL-3B 固定维度
# 或者动态获取:
# hidden = self.vlm.config.hidden_size我建议你用方案三(4-bit 量化)+ 修复 hidden 维度,改动最少、效果最好,8GB 显存完全够用。
代码详解
Kaiyi,这是一个非常好的学习切入点。这段代码虽然只有不到200行,但它浓缩了VLA(Vision-Language-Action)端到端自动驾驶的核心思想。我来从最底层开始,一层一层讲透。
我先把整体脉络梳理清楚,然后逐块深入。
一、这段代码到底在干什么?
用一句话概括:让一个"能看图、能读字"的AI模型,学会根据摄像头画面和驾驶指令,预测车未来应该走的路线。
拆开来说,这段代码做了三件事:
第一件:从 nuScenes 数据集里取出真实驾驶数据——前方摄像头拍到的照片、当时的驾驶指令(直行/左转/右转)、车速、以及车实际走过的轨迹。
第二件:搭建一个 MiniVLA 模型——把一个已经训练好的"看图说话"大模型(Qwen2.5-VL)当作"眼睛和大脑",在它上面接一个小的轨迹预测头。
第三件:训练这个轨迹预测头——让它通过反复看真实驾驶数据,学会输出合理的未来轨迹。
这就是 VLA 的核心范式:Vision(看)→ Language(理解指令)→ Action(输出动作)。
二、前置知识:你需要先理解的几个概念
2.1 什么是轨迹(Trajectory)?
开车时,你的车从现在的位置出发,未来几秒会经过一系列位置点。把这些点连起来,就是"轨迹"。
现在位置 → 0.5秒后位置 → 1秒后位置 → ... → 3秒后位置
(0, 0) (1.2, 0.1) (2.5, 0.3) (8.1, 1.2)每个位置用 (x, y) 坐标表示。这段代码预测 6 个未来位置点,每个点有 x 和 y 两个值,所以模型的输出形状是 (6, 2) —— 6个点,每点2个坐标。
2.2 什么是 VLM(Vision-Language Model)?
VLM 就是"视觉-语言模型",它能同时理解图片和文字。你给它一张猫的照片加一句"这是什么?",它能回答"这是一只橘猫"。
代码里用的 Qwen2.5-VL 就是这样一个模型。它内部有两个核心部分:一个视觉编码器(把图片变成数字特征),一个语言模型(理解文字并生成回答)。两者的特征最终融合在一起。
2.3 什么是 VLA(Vision-Language-Action)?
VLA 是在 VLM 基础上的延伸。VLM 的输出是文字(比如回答问题),而 VLA 的输出是动作(比如驾驶轨迹、机器人关节角度)。
做法其实很简单:把 VLM 当作一个强大的"特征提取器",它理解了图片和指令后会产生一个高维特征向量,然后在这个特征上面接一个小网络(叫"动作头"或"轨迹头"),把特征转换成具体的动作。
图片 + "直行" ──→ [VLM 理解场景] ──→ 特征向量 ──→ [轨迹头] ──→ 6个坐标点2.4 什么是"冻结"模型参数(freeze)?
VLM 有几十亿个参数,是在海量数据上训练好的。如果训练时把这些参数也一起更新,一来需要巨大的显存,二来容易把已经学好的能力破坏掉。
所以代码里 freeze_vlm=True 的意思是:VLM 的参数"锁死",训练时只更新轨迹头那几千个参数。这就像请了一个经验丰富的老司机(VLM)来看路况并描述,你只需要训练一个翻译(轨迹头)把老司机的描述翻译成方向盘操作。
2.5 什么是 nuScenes 数据集?
nuScenes 是自动驾驶领域最知名的公开数据集之一,由 Motional(前 nuTonomy)公司在波士顿和新加坡的真实道路上采集。包含1000个驾驶场景,每辆数据采集车上装了 6 个摄像头、1 个激光雷达、5 个毫米波雷达等传感器。
代码里用的是 v1.0-mini,这是一个只有 10 个场景、404 个样本的迷你版,专门用来调试代码。
三、逐块代码详解
3.1 环境变量设置
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
os.environ["TRANSFORMERS_OFFLINE"] = "0"
os.environ['HUGGINGFACE_HUB_CACHE'] = './model_cache'这几行必须在 import transformers 之前设置。HF_ENDPOINT 把 HuggingFace 的下载地址切换到国内镜像,否则在国内下载模型会非常慢或者根本连不上。HUGGINGFACE_HUB_CACHE 指定模型缓存目录,避免每次都重新下载。
3.2 数据集类:NuScenesTrajDataset
这是整个代码的数据供给管道。PyTorch 要求数据集继承 Dataset 类,并实现三个方法。
__init__:初始化
def __init__(self, nusc_root, nusc_version='v1.0-mini', seq_len=6, max_samples=100):
self.nusc = NuScenes(version=nusc_version, dataroot=nusc_root, verbose=True)
self.seq_len = seq_len
self.sample_tokens = [s['token'] for s in self.nusc.sample]
self.sample_tokens = self.sample_tokens[:max_samples]NuScenes(...) 加载数据集的元数据(不是直接加载所有图片,而是加载索引表,真正的图片在 __getitem__ 时才按需读取)。
token 是 nuScenes 里每条数据的唯一标识符(一串十六进制字符串),类似于数据库的主键。所有数据都通过 token 互相关联。
max_samples=100 只取前100条数据,这是为了快速调试。完整的 mini 版有 404 条。
__getitem__:取一条数据
这个方法在训练时被反复调用,每次返回一条训练样本。
加载图像部分:
cam_data = self.nusc.get('sample_data', sample['data']['CAM_FRONT'])
cam_path = os.path.join(self.nusc.dataroot, cam_data['filename'])
image = Image.open(cam_path).convert('RGB')nuScenes 的数据组织方式是:sample(一个时间戳的完整数据)→ sample_data(某个传感器在这个时间戳的数据)。sample['data']['CAM_FRONT'] 取出前视摄像头的数据 token,然后通过 nusc.get() 获取详细信息(包括文件路径),最后用 PIL 打开图片。
生成驾驶指令部分:
ego_pose = self.nusc.get('ego_pose', cam_data['ego_pose_token'])
yaw = Quaternion(ego_pose['rotation']).yaw_pitch_roll[0]
if -0.3 < yaw < 0.3:
command = "drive straight"
elif yaw >= 0.3:
command = "turn left"
else:
command = "turn right"这里有一个重要概念——四元数(Quaternion)。三维空间中表示旋转有很多方式(欧拉角、旋转矩阵、四元数等),nuScenes 用的是四元数,因为它没有万向节死锁问题。
yaw 是偏航角,也就是车头朝向。想象你站在车顶往下看,车头指向正前方时 yaw=0,向左偏时 yaw>0,向右偏时 yaw<0。代码根据 yaw 角简单判断当前是直行、左转还是右转。
注意:这个判断是非常粗糙的简化。真正的驾驶指令应该来自导航系统(比如"200米后右转"),这里只是为了教学演示。
加载未来轨迹部分:
traj = np.zeros((self.seq_len, 2), dtype=np.float32)
current_token = self.sample_tokens[idx]
for i in range(self.seq_len):
if current_token in self.nusc.sample:
next_sample = self.nusc.get('sample', current_token)
next_cam = self.nusc.get('sample_data', next_sample['data']['CAM_FRONT'])
next_pose = self.nusc.get('ego_pose', next_cam['ego_pose_token'])
traj[i] = [next_pose['translation'][0], next_pose['translation'][1]]
current_token = next_sample.get('next', '')nuScenes 的 sample 之间通过 next 字段形成链表结构。从当前帧出发,沿着 next 往后走 6 步,记录每步的 ego_pose(自车在全局坐标系中的位置),这就是"真实轨迹"——也就是人类司机实际开过的路线。
轨迹归一化:
current_trans = np.array(ego_pose['translation'][:2])
traj = traj - current_trans[None, :]全局坐标可能是 (1035.2, 567.8) 这样的大数。减去当前位置后,轨迹变成相对坐标,比如 (1.2, 0.3) 表示"未来往前1.2米、往右0.3米"。这对模型训练非常重要,因为模型不需要知道自己在地球上的绝对位置,只需要知道"接下来往哪走"。
这里有一个 bug
if current_token in self.nusc.sample:self.nusc.sample 是一个列表(list of dict),而 current_token 是字符串。in 操作符在列表上做的是遍历比较,它会检查 token 字符串是否等于列表中的某个 dict——这永远是 False。正确的做法应该是用 self.nusc.get('sample', current_token) 加 try-except,或者预先构建 token 集合。不过在 mini 数据集上如果恰好没触发这个分支,可能不会立即报错,但轨迹会全是零。
3.3 模型类:MiniVLA
构造函数 __init__
self.vlm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
vlm_name,
torch_dtype=torch.float16,
trust_remote_code=True)
self.processor = AutoProcessor.from_pretrained(vlm_name, trust_remote_code=True)from_pretrained 从 HuggingFace 加载预训练好的模型权重。torch.float16 用半精度浮点数,每个参数占2字节而不是4字节,省一半显存。AutoProcessor 是配套的数据预处理器,负责把图片缩放裁剪、把文字转成 token ID。
if freeze_vlm:
for p in self.vlm.parameters():
p.requires_grad = Falserequires_grad = False 告诉 PyTorch:反向传播时不要计算这些参数的梯度。这样不仅省显存(不需要存梯度),还防止把预训练好的知识破坏。
self.traj_head = nn.Sequential(
nn.Linear(hidden, 512), nn.ReLU(), nn.Dropout(0.1),
nn.Linear(512, 256), nn.ReLU(),
nn.Linear(256, num_waypoints * 2) # 6*2=12
)轨迹头是一个三层的全连接网络(MLP):
- 第一层:2048维 → 512维(降维),ReLU 激活(把负数变0,引入非线性),Dropout 0.1(训练时随机丢掉10%的神经元,防止过拟合)
- 第二层:512维 → 256维
- 第三层:256维 → 12维(6个点 × 2个坐标)
前向传播 forward
prompts = [f'Command: {cmd}. Speed: {sp:.1f}m/s.'
for cmd, sp in zip(driving_commands, ego_speeds)]把驾驶指令和速度拼成文本提示。比如 "Command: drive straight. Speed: 5.0m/s."。这就是 VLA 中 "Language" 的部分——用自然语言告诉模型当前的驾驶意图。
inputs = self.processor(
text=prompts,
images=images,
return_tensors='pt',
padding=True
).to(self.vlm.device)Processor 做了很多事:把图片缩放到模型要求的尺寸、归一化像素值、把文字分词(tokenize)成数字 ID、对批次中不同长度的序列做 padding(补齐到相同长度)。最后 .to(device) 搬到 GPU 上。
with torch.no_grad():
out = self.vlm(**inputs, output_hidden_states=True)torch.no_grad() 表示这个计算过程不需要记录梯度(因为 VLM 参数已冻结)。output_hidden_states=True 让模型返回每一层 Transformer 的隐藏状态,而不仅仅是最终的 logits。
h = out.hidden_states[-1][:, -1, :].float()这行信息量很大:
out.hidden_states是一个元组,包含每层 Transformer 的输出[-1]取最后一层——最后一层包含最丰富的语义信息[:, -1, :]取序列中最后一个 token 的特征——在自回归语言模型中,最后一个 token 聚合了前面所有 token 的信息(通过 attention 机制).float()从 fp16 转回 fp32,因为轨迹头用 fp32 计算更稳定
所以 h 的形状是 (batch_size, 2048)——一个浓缩了"图像理解 + 指令理解"的特征向量。
traj = self.traj_head(h)
return traj.view(-1, 6, 2)特征向量经过轨迹头,输出 (batch_size, 12) 的向量,然后 reshape 成 (batch_size, 6, 2)——每个样本 6 个轨迹点,每点 2 个坐标。
3.4 训练函数 train()
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
pin_memory=True
)DataLoader 负责从 Dataset 中批量取数据。shuffle=True 每个 epoch 打乱顺序(防止模型记住数据顺序而非学到规律)。num_workers=2 用两个子进程并行加载数据。pin_memory=True 把数据放在 page-locked 内存中,加速 CPU→GPU 的传输。
optimizer = torch.optim.Adam(model.traj_head.parameters(), lr=LR)只优化 traj_head 的参数。Adam 优化器是 SGD 的改进版,自适应调整每个参数的学习率,在实践中收敛更快。
loss_fn = nn.SmoothL1Loss()SmoothL1Loss(也叫 Huber Loss)结合了 L1 和 L2 损失的优点:当预测和真实值差距大时用 L1(不会像 L2 那样产生过大梯度),差距小时用 L2(比 L1 更平滑,有利于精细优化)。对轨迹预测这种回归任务来说是很好的选择。
训练循环:
for epoch in range(EPOCHS):
for images, commands, speeds, gt_traj in pbar:
gt_traj = gt_traj.to(DEVICE) # 真实轨迹搬到GPU
pred_traj = model(images, commands, speeds) # 前向:预测轨迹
loss = loss_fn(pred_traj, gt_traj) # 算损失:预测 vs 真实
optimizer.zero_grad() # 清空上一步的梯度
loss.backward() # 反向传播:计算梯度
optimizer.step() # 更新参数这就是深度学习训练的标准套路,每一步做五件事:
- 数据送入模型,得到预测结果
- 预测结果和真实答案对比,算出"错了多少"(loss)
- 清空旧梯度(PyTorch 默认累加梯度)
- 反向传播计算每个参数对 loss 的贡献(梯度)
- 按梯度方向更新参数(让 loss 变小)
重复这个过程,模型就逐渐学会预测正确的轨迹。
四、整体数据流总结
nuScenes 数据集
│
├── 前视摄像头图片 (1600×900 RGB)
├── 驾驶指令 ("drive straight")
├── 车速 (5.0 m/s)
└── 真实轨迹 (6个xy坐标)
│
▼
┌─────────────────────────┐
│ MiniVLA 模型 │
│ │
│ 图片+指令 → Processor │
│ → Qwen2.5-VL │ ← 冻结,不训练
│ → 2048维特征 │
│ → 轨迹头(MLP) │ ← 只训练这部分
│ → 6×2 轨迹坐标 │
└─────────────────────────┘
│
▼
SmoothL1Loss(预测轨迹, 真实轨迹) → 梯度 → 更新轨迹头参数五、这段代码的局限性
作为教学代码,它做了大量简化,了解这些局限性对你写书很有价值:
驾驶指令太粗糙:只有三种(直行/左转/右转),真实 VLA 系统(如 RT-2、LINGO-1)使用更丰富的自然语言指令。
只用一个摄像头:真实自动驾驶用 6 个摄像头做环视感知,这里只用了前视。
速度是硬编码的:speed = 5.0 写死了,真实速度应该从 CAN bus 数据读取。
轨迹 bug:前面提到的 if current_token in self.nusc.sample 大概率导致轨迹全是零向量。
没有数据增强:真实训练会对图片做随机裁剪、颜色抖动、翻转等增强。
不过作为一个 "用不到200行代码跑通 VLA 全流程" 的教学示例,它的价值在于让你清晰看到 Vision-Language-Action 三者如何串联,这个架构思路和 Tesla FSD、小鹏 VLA 的核心思想是一致的。
Fake数据
vla_fake_datasets.py
import os
# ===================== 【国内核心设置】全局切换为国内镜像 Qwen2.5-VL=====================
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # huggingface 国内镜像
os.environ["TRANSFORMERS_OFFLINE"] = "0"
os.environ['HUGGINGFACE_HUB_CACHE'] = './model_cache'
os.environ['TRANSFORMERS_CACHE'] = './model_cache'
os.environ['HF_HUB_DOWNLOAD_TIMEOUT'] = '600'
# ================ 之后才能 import 其他库 ================
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from nuscenes import NuScenes
from nuscenes.utils.data_classes import LidarPointCloud, Box
from nuscenes.utils.geometry_utils import transform_matrix
from pyquaternion import Quaternion
import numpy as np
from PIL import Image
from tqdm import tqdm
import warnings
warnings.filterwarnings("ignore")
# ===================== 1. 修复:NuScenes 数据集定义 =====================
class NuScenesTrajDataset(Dataset):
"""
NuScenes 数据集:加载相机图像 + 驾驶指令 + 自车速度 + 真实轨迹
简化版:取前视相机图像,预测未来6个轨迹点 (x,y)
#【核心改动】只加载前 N 条数据的小数据集
"""
def __init__(self, nusc_root, nusc_version='v1.0-mini', seq_len=6, max_samples=100):
self.nusc = NuScenes(version=nusc_version, dataroot=nusc_root, verbose=True)
self.seq_len = seq_len # 预测6个轨迹点
self.sample_tokens = [s['token'] for s in self.nusc.sample]
# ================ ✅ 关键:只取前 N 个样本 ================
self.sample_tokens = self.sample_tokens[:max_samples]
print(f"✅ 只加载数据集前 {max_samples} 条!")
def __len__(self):
return len(self.sample_tokens)
def __getitem__(self, idx):
"""加载单帧数据:图像、指令、速度、真实轨迹"""
sample = self.nusc.get('sample', self.sample_tokens[idx])
# ========== 1. 加载前视相机图像 ==========
cam_data = self.nusc.get('sample_data', sample['data']['CAM_FRONT'])
cam_path = os.path.join(self.nusc.dataroot, cam_data['filename'])
image = Image.open(cam_path).convert('RGB')
# ========== 2. 生成驾驶指令(简化:直行/左转/右转) ==========
ego_pose = self.nusc.get('ego_pose', cam_data['ego_pose_token'])
yaw = Quaternion(ego_pose['rotation']).yaw_pitch_roll[0]
if -0.3 < yaw < 0.3:
command = "drive straight"
elif yaw >= 0.3:
command = "turn left"
else:
command = "turn right"
# ========== 3. 自车速度(简化:固定/从数据集读取) ==========
speed = 5.0 # m/s
# ========== 4. 加载未来真实轨迹 (x,y) 6个点 ==========
traj = np.zeros((self.seq_len, 2), dtype=np.float32)
current_token = self.sample_tokens[idx]
for i in range(self.seq_len):
if current_token in self.nusc.sample:
next_sample = self.nusc.get('sample', current_token)
next_cam = self.nusc.get('sample_data', next_sample['data']['CAM_FRONT'])
next_pose = self.nusc.get('ego_pose', next_cam['ego_pose_token'])
traj[i] = [next_pose['translation'][0], next_pose['translation'][1]]
current_token = next_sample.get('next', '')
# 轨迹归一化(相对于当前自车位置)
current_trans = np.array(ego_pose['translation'][:2])
traj = traj - current_trans[None, :]
return image, command, np.float32(speed), torch.from_numpy(traj)
# ===================== 2. 修复:模型批量处理 + 训练适配 =====================
class MiniVLA(nn.Module):
def __init__(self, vlm_name='Qwen/Qwen2.5-VL-7B-Instruct',
num_waypoints=6, freeze_vlm=True):
super().__init__()
print("✅ 从国内镜像加载模型...")
# 加载预训练 VLM
self.vlm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
vlm_name,
torch_dtype=torch.float16,
trust_remote_code=True)
self.processor = AutoProcessor.from_pretrained(vlm_name,
trust_remote_code=True)
# 冻结 VLM 参数
if freeze_vlm:
for p in self.vlm.parameters():
p.requires_grad = False
# 轨迹预测头
# hidden = self.vlm.config.hidden_sizes
# hidden = self.vlm.config.hidden_sizes[-1]
# ===================== ✅ 终极修复:Qwen2.5-VL 正确维度 =====================
# 3B 模型 = 2048,7B 模型 = 3584,直接写死最稳定
# hidden = 2048 # Qwen2.5-VL-3B 固定维度
hidden = 3584 # 如果用 7B 模型就打开这个
self.traj_head = nn.Sequential(
nn.Linear(hidden, 512), nn.ReLU(), nn.Dropout(0.1),
nn.Linear(512, 256), nn.ReLU(),
nn.Linear(256, num_waypoints * 2)
)
def forward(self, images, driving_commands, ego_speeds):
"""批量处理修复:支持多张图像+多个指令"""
# 构建批量 prompt
prompts = [f'Command: {cmd}. Speed: {sp:.1f}m/s.'
for cmd, sp in zip(driving_commands, ego_speeds)]
# 批量预处理
inputs = self.processor(
text=prompts,
images=images,
return_tensors='pt',
padding=True
).to(self.vlm.device)
# 提取 VLM 特征
with torch.no_grad():
out = self.vlm(**inputs, output_hidden_states=True)
# 取最后一层最后一个 token 特征
h = out.hidden_states[-1][:, -1, :].float()
traj = self.traj_head(h)
return traj.view(-1, 6, 2) # (B, 6, 2)
# ===================== 3. 修复:完整训练流程(含 Dataloader) =====================
def train():
# ========== 配置参数 ==========
NUSCENES_ROOT = "/home/lionsking/data/nuscenes" # 你自己的 NuScenes 数据集路径
BATCH_SIZE = 1
EPOCHS = 20
LR = 1e-3
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# ========== 加载数据集 ==========
dataset = NuScenesTrajDataset(nusc_root=NUSCENES_ROOT)
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=2,
pin_memory=True
)
# ========== 模型、优化器、损失 ==========
model = MiniVLA(freeze_vlm=True).to(DEVICE)
optimizer = torch.optim.Adam(model.traj_head.parameters(), lr=LR)
loss_fn = nn.SmoothL1Loss()
# ========== 训练循环 ==========
print("开始训练...")
model.train()
for epoch in range(EPOCHS):
total_loss = 0.0
pbar = tqdm(dataloader, desc=f"Epoch {epoch+1}/{EPOCHS}")
for images, commands, speeds, gt_traj in pbar:
# 数据搬到 GPU
gt_traj = gt_traj.to(DEVICE)
# 前向 + 损失
pred_traj = model(images, commands, speeds)
loss = loss_fn(pred_traj, gt_traj)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
pbar.set_postfix(loss=loss.item())
avg_loss = total_loss / len(dataloader)
print(f"Epoch {epoch+1} 平均损失: {avg_loss:.4f}")
# 保存训练好的轨迹头
torch.save(model.traj_head.state_dict(), 'vla_traj_head.pth')
print("训练完成,模型已保存为 vla_traj_head.pth")
if __name__ == "__main__":
train()
训练日志:
(carla) lionsking@ai-dev:~/Code/auto_self$ python vla_fake_datasets.py
✅ 加载模型(低显存版)...
Fetching 5 files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 5/5 [00:00<00:00, 8676.67it/s]
Download complete: : 0.00B [00:00, ?B/s] | 0/5 [00:00<?, ?it/s]
Loading weights: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 729/729 [00:02<00:00, 266.61it/s]
Some parameters are on the meta device because they were offloaded to the cpu.
🚀 开始训练(8G 显卡专用)...
Epoch 1: 0%| | 0/200 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/home/lionsking/Code/auto_self/vla_fake_datasets.py", line 116, in <module>
train()
File "/home/lionsking/Code/auto_self/vla_fake_datasets.py", line 97, in train
for images, commands, speeds, gt_traj in pbar:
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/tqdm/std.py", line 1181, in __iter__
for obj in iterable:
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 741, in __next__
data = self._next_data()
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/utils/data/dataloader.py", line 801, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/utils/data/_utils/fetch.py", line 57, in fetch
return self.collate_fn(data)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/utils/data/_utils/collate.py", line 401, in default_collate
return collate(batch, collate_fn_map=default_collate_fn_map)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/utils/data/_utils/collate.py", line 214, in collate
return [
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/utils/data/_utils/collate.py", line 215, in <listcomp>
collate(samples, collate_fn_map=collate_fn_map)
File "/home/lionsking/miniconda3/envs/carla/lib/python3.10/site-packages/torch/utils/data/_utils/collate.py", line 243, in collate
raise TypeError(default_collate_err_msg_format.format(elem_type))
TypeError: default_collate: batch must contain tensors, numpy arrays, numbers, dicts or lists; found <class 'PIL.Image.Image'>
(carla) lionsking@ai-dev:~/Code/auto_self$
(carla) lionsking@ai-dev:~/Code/auto_self$ 为者常成,行者常至
自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)



